Go 部落格
Go 的垃圾回收器之旅:起步
這是我於2018年6月18日在國際記憶體管理會議(ISMM)上發表的主題演講的文字記錄。在過去的25年裡,ISMM一直是釋出記憶體管理和垃圾回收論文的首選場所,我很榮幸能受邀發表演講。
摘要
Go 語言的特性、目標和用例迫使我們重新思考整個垃圾回收機制,並將我們帶到了一個令人驚訝的境地。這段旅程令人振奮。本次演講將描述我們的旅程。這是一段由開源和谷歌生產需求驅動的旅程。我們還將會探討一些走入死衚衕的“峽谷”,但數字最終指引了我們回家。本次演講將深入探討我們旅程的“如何”和“為什麼”,我們在2018年的現狀,以及 Go 為旅程的下一段所做的準備。
簡介
Richard L. Hudson (Rick) 以其在記憶體管理方面的工作而聞名,包括髮明瞭 Train、Sapphire 和 Mississippi Delta 演算法以及 GC 棧對映,這些技術使得在 Modula-3、Java、C# 和 Go 等靜態型別語言中能夠進行垃圾回收。Rick 目前是谷歌 Go 團隊的一員,負責 Go 的垃圾回收和執行時問題。
聯絡方式: rlh@golang.org
評論: 請參閱 golang-dev 上的討論。
文字記錄

我是 Rick Hudson。
這是一場關於 Go 執行時,特別是垃圾回收器的演講。我準備了大約45到50分鐘的材料,之後將有時間進行討論,我也會在場,所以歡迎大家會後過來交流。

在開始之前,我想感謝一些人。
演講中很多精彩的內容都出自 Austin Clements 之手。來自劍橋 Go 團隊的 Russ、Than、Cherry 和 David 是一群令人興奮且有趣的工作夥伴。
我們還要感謝全球160萬 Go 使用者,他們為我們提供了有趣的問題來解決。沒有他們,很多問題就不會浮出水面。
最後,我要感謝 Renee French,感謝她多年來創作的這些可愛的 Gophers。在演講中你會看到好幾個。

在我們深入探討這些內容之前,我們真的需要看看 GC 眼中的 Go 是什麼樣子的。

首先,Go 程式擁有數十萬個棧。它們由 Go 排程器管理,並且總是在 GC 安全點被搶佔。Go 排程器將 Go 程複用(multiplex)到 OS 執行緒上,通常一個 OS 執行緒對應一個硬體執行緒。我們透過複製棧並更新棧中的指標來管理棧及其大小。這是一個區域性操作,因此擴充套件性相當好。

接下來重要的是 Go 是一種面向值(value-oriented)的語言,遵循 C 風格系統語言的傳統,而不是大多數託管執行時語言的面向引用(reference-oriented)語言的傳統。例如,這展示了 `tar` 包中的一個型別在記憶體中的佈局。所有欄位都直接嵌入在 `Reader` 值中。這使得程式設計師在需要時可以更好地控制記憶體佈局。可以將相關的欄位放在一起,這有助於提高快取區域性性。
面向值也有助於外部函式介面(FFI)。我們擁有與 C 和 C++ 的快速 FFI。顯然,谷歌擁有大量可用設施,但它們是用 C++ 編寫的。Go 迫不及待地想用 Go 重新實現所有這些東西,所以 Go 必須透過外部函式介面訪問這些系統。
這個設計決策導致了執行時中一些非常了不起的事情。它可能是 Go 與其他 GC 語言最顯著的區別。
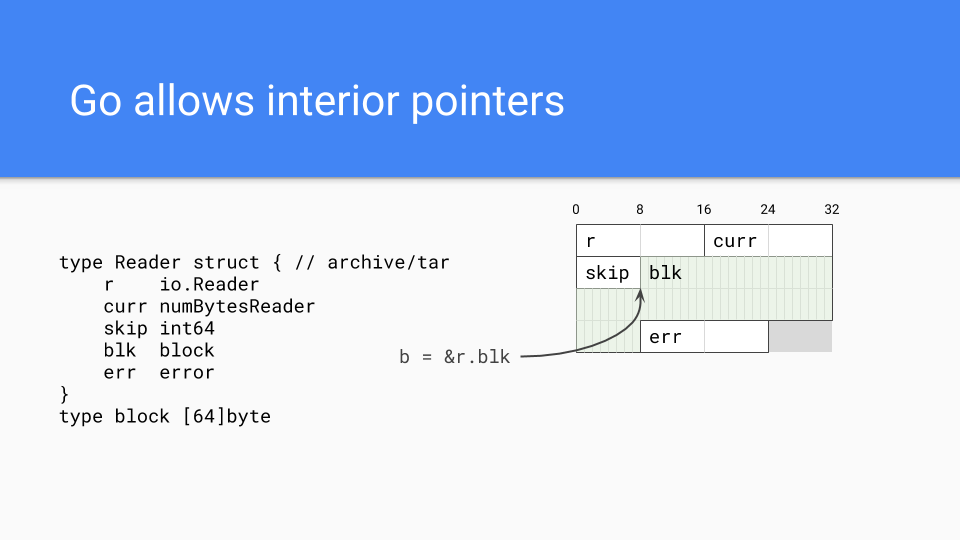
當然,Go 可以擁有指標,事實上它們可以擁有內部指標。這類指標會使整個值保持活躍,並且相當常見。

我們還有一個提前編譯系統,所以二進位制檔案包含了整個執行時。
沒有 JIT 重編譯。這有利有弊。首先,程式執行的可復現性大大提高,這使得編譯器改進的進展更快。
另一方面,我們無法像 JIT 系統那樣進行反饋最佳化。
所以有利有弊。

Go 提供了兩個控制 GC 的“旋鈕”。第一個是 `GCPercent`。本質上,它是一個用來調整 CPU 使用量和記憶體使用量的旋鈕。預設值為 100,這意味著堆的一半用於存放活動記憶體,一半用於分配。你可以向任一方向調整它。
`MaxHeap`(尚未釋出,但正在內部使用和評估)允許程式設計師設定最大堆大小。記憶體不足 (OOM) 對 Go 來說是棘手的;記憶體使用量的暫時性峰值應該透過增加 CPU 成本來處理,而不是透過中止。基本上,如果 GC 檢測到記憶體壓力,它會通知應用程式應該解除安裝負載。一旦情況恢復正常,GC 會通知應用程式可以恢復正常負載。`MaxHeap` 還提供了更大的排程靈活性。執行時不再總是擔心可用記憶體量,而是可以將堆大小擴充套件到 `MaxHeap`。
以上是我們對 Go 中與垃圾回收器相關的部分進行的討論。

現在,讓我們來談談 Go 執行時,以及我們是如何走到今天這一步的。

那是 2014 年。如果 Go 不能以某種方式解決 GC 延遲問題,那麼 Go 就不會成功。這一點很明確。
其他新興語言也面臨著同樣的問題。Rust 等語言選擇了不同的道路,但我們將討論 Go 所走的道路。
為什麼延遲如此重要?

數學上對此毫無通融之處。
99%ile 的獨立 GC 延遲服務等級目標(SLO),例如 GC 週期 99% 的時間小於 10ms,根本無法擴充套件。重要的是整個會話期間或一天中多次使用應用程式時的延遲。假設一個瀏覽了多個網頁的會話,在會話期間進行了 100 次伺服器請求,或者進行了 20 次請求,並且一天中有 5 個這樣的會話。在這種情況下,只有 37% 的使用者在整個會話中都能獲得一致的低於 10ms 的體驗。
如果我們建議 99% 的使用者獲得低於 10ms 的體驗,數學表明您實際上需要瞄準 4 個 9,即 99.99%ile。
所以,那是 2014 年,Jeff Dean 剛剛釋出了他的論文《The Tail at Scale》,這篇文章對此進行了更深入的探討。由於其對谷歌未來的嚴重影響以及谷歌的擴充套件規模,這篇論文在谷歌被廣泛閱讀。
我們將這個問題稱為“9 的暴政”。

那麼,如何對抗“9 的暴政”呢?
在 2014 年,人們已經做了很多事情。
如果你想要 10 個答案,就多問幾個,然後取前 10 個,將這些答案放在搜尋頁面上。如果請求超過 50%ile,就重新發出請求或將其轉發給另一個伺服器。如果 GC 即將執行,就拒絕新請求或將請求轉發給另一個伺服器,直到 GC 完成。依此類推。
所有這些變通方法都源於非常有才華的人們面臨的非常真實的問題,但它們並沒有解決 GC 延遲的根本問題。在谷歌的規模下,我們必須解決根本問題。為什麼?

冗餘無法擴充套件,冗餘成本高昂。它需要新的伺服器場。
我們希望能夠解決這個問題,並將其視為改進伺服器生態系統的機會,同時保護一些瀕危的玉米地,讓一粒玉米有機會在七月四日達到膝蓋高,並充分發揮其潛力。

這是 2014 年的 SLO。是的,事實是我故意保守了目標,我剛加入團隊,對我來說這是一個新流程,我不想過度承諾。
此外,關於其他語言中 GC 延遲的演示簡直太可怕了。

最初的計劃是做一個無讀屏障的併發複製 GC。那是長遠計劃。人們對讀屏障的開銷存在很大的不確定性,因此 Go 希望避免使用它們。
但在 2014 年的短期內,我們必須團結起來。我們必須將所有執行時和編譯器都轉換為 Go 語言。當時它們是用 C 編寫的。不再有 C,不再有由於 C 程式設計師不理解 GC 但對如何複製字串有奇思妙想而導致的長期 bug。我們還需要快速得到一些東西,並專注於延遲,但效能損失必須小於編譯器帶來的提速。所以我們受到限制。我們基本上只有一年的編譯器效能提升空間,可以被 GC 併發所抵消。但僅此而已。我們不能減慢 Go 程式的執行速度。在 2014 年,這將是不可容忍的。

所以我們稍作退讓。我們不打算進行復制部分。
決定採用三色併發演算法。在我職業生涯的早期,我和 Eliot Moss 進行了期刊證明,證明了 Dijkstra 演算法可以與多個應用程式執行緒協同工作。我們還證明了可以消除 STW(Stop The World)問題,並且有證明可以做到。
我們還擔心編譯器速度,即編譯器生成的程式碼。如果大部分時間保持寫屏障關閉,對編譯器最佳化的影響將最小,編譯器團隊可以快速推進。Go 在 2015 年也迫切需要短期成功。
那麼,讓我們來看看我們做的一些事情。
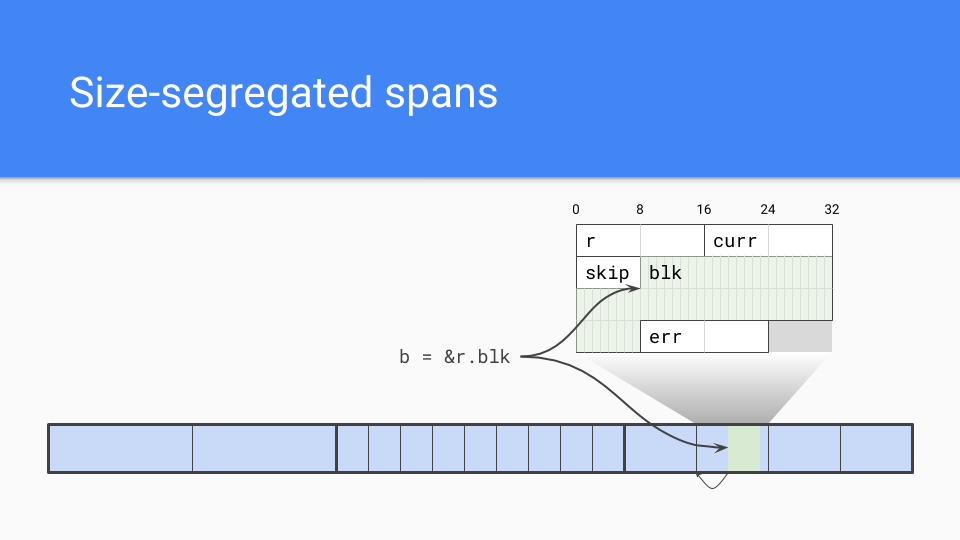
我們採用了按大小劃分的 Span(span)。內部指標是個問題。
垃圾回收器需要有效地找到物件的起始位置。如果知道 Span 中物件的大小,它只需向下取整到該大小,那就是物件的起始位置。
當然,按大小劃分的 Span 還有其他優點。
低碎片化:根據 C 的經驗,以及谷歌的 TCMalloc 和 Hoard,我曾深入參與 Intel 的 Scalable Malloc,這項工作讓我們有信心,碎片化不會成為非移動分配器的問題。
內部結構:我們完全理解並有經驗。我們知道如何進行按大小劃分的 Span,如何進行低爭用或零爭用的分配路徑。
速度:非移動不讓我們擔心,分配速度可能有所放慢,但仍在 C 的數量級。可能不如指標推進(bump pointer)快,但還可以接受。
我們還有外部函式介面問題。如果我們不移動物件,那麼在嘗試固定物件並將間接層放在 C 和正在處理的 Go 物件之間時,我們就不必處理移動收集器可能遇到的長期 bug。

下一個設計選擇是將物件的元資料放在哪裡。由於沒有頭部,我們需要一些關於物件的資訊。標記位(Mark bits)儲存在旁邊,用於標記和分配。每個字(word)有 2 位與之關聯,用來告訴您該字是標量(scalar)還是指標。它還編碼了物件中是否還有更多指標,這樣我們就可以更快地停止掃描物件。我們還有一個額外的位編碼,可以用作額外的標記位或用於其他除錯。這對啟動和查詢 bug 非常有價值。

那麼,寫屏障(write barrier)呢?寫屏障僅在 GC 期間開啟。其他時候,編譯後的程式碼會載入一個全域性變數並檢視它。由於 GC 通常是關閉的,硬體會正確地預測並繞過寫屏障。當我們處於 GC 狀態時,該變數不同,寫屏障負責確保在三色操作期間不會丟失任何可達物件。

程式碼的另一部分是 GC Pacer。這是 Austin 完成的一些很棒的工作。它基本上基於一個反饋迴圈,該迴圈確定何時最佳地啟動 GC 週期。如果系統處於穩定狀態而不是處於階段變化中,標記將在記憶體耗盡時結束。
情況可能並非如此,因此 Pacer 還必須監控標記進度,並確保分配不會超過併發標記。
如有必要,Pacer 會減慢分配速度,同時加快標記速度。在高層次上,Pacer 會暫停大量分配的 Goroutine,並讓其進行標記工作。工作量與 Goroutine 的分配量成正比。這會加速垃圾回收器,同時減慢變異器(mutator)。
完成所有這些後,Pacer 會將其從當前 GC 週期和之前的週期中學到的知識用於預測何時啟動下一個 GC。
它做得遠不止這些,但這只是基本方法。
數學絕對引人入勝,請聯絡我獲取設計文件。如果您正在開發併發 GC,您絕對應該看看這些數學原理,看看是否與您的數學原理相同。如果您有任何建議,請告訴我們。
*Go 1.5 併發垃圾回收器 Pacing 和 提案:區分軟堆限制和硬堆限制

是的,我們取得了成功,很多成功。一個年輕、更瘋狂的 Rick 會把這些圖表紋在我的肩膀上,因為我太自豪了。
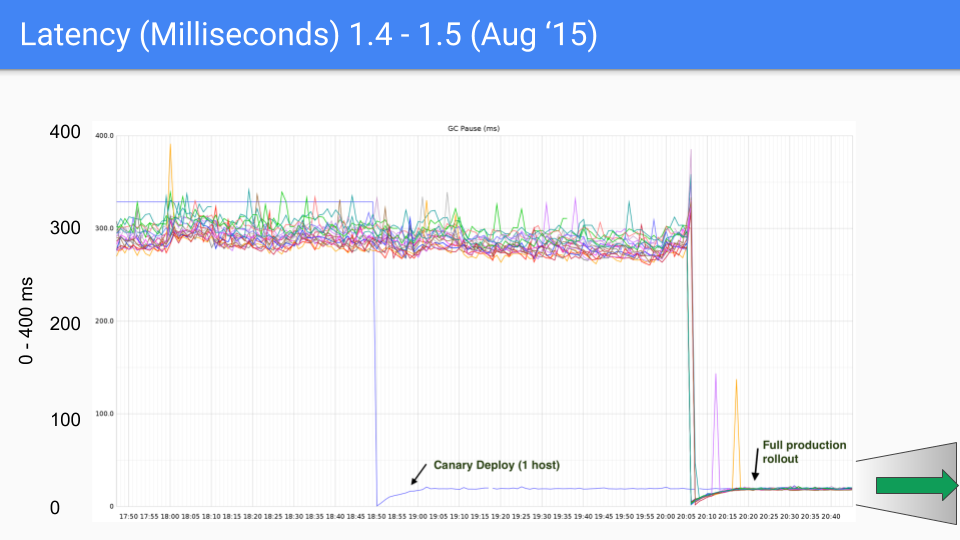
這是一系列為 Twitter 生產伺服器繪製的圖表。當然,我們與該生產伺服器無關。Brian Hatfield 進行了這些測量,並意外地在 Twitter 上釋出了它們。
Y 軸是 GC 延遲(毫秒)。X 軸是時間。每個點都是該 GC 期間的“停止世界”(stop the world)暫停時間。
在我們 2015 年 8 月的第一個版本中,我們看到延遲從大約 300-400 毫秒下降到 30-40 毫秒。這很好,數量級上有了很大提升。
我們將 Y 軸從 0 到 400 毫秒大幅度地改為 0 到 50 毫秒。

這是 6 個月後。這次改進主要是由於系統性地消除了我們在“停止世界”期間進行的所有 O(heap) 操作。這是我們第二次數量級改進,從 40 毫秒下降到 4-5 毫秒。

其中存在一些 bug 需要修復,我們在次要版本 1.6.3 中完成了這些工作。這將延遲降低到遠低於 10 毫秒,達到了我們的 SLO。
我們即將再次更改 Y 軸,這次改為 0 到 5 毫秒。
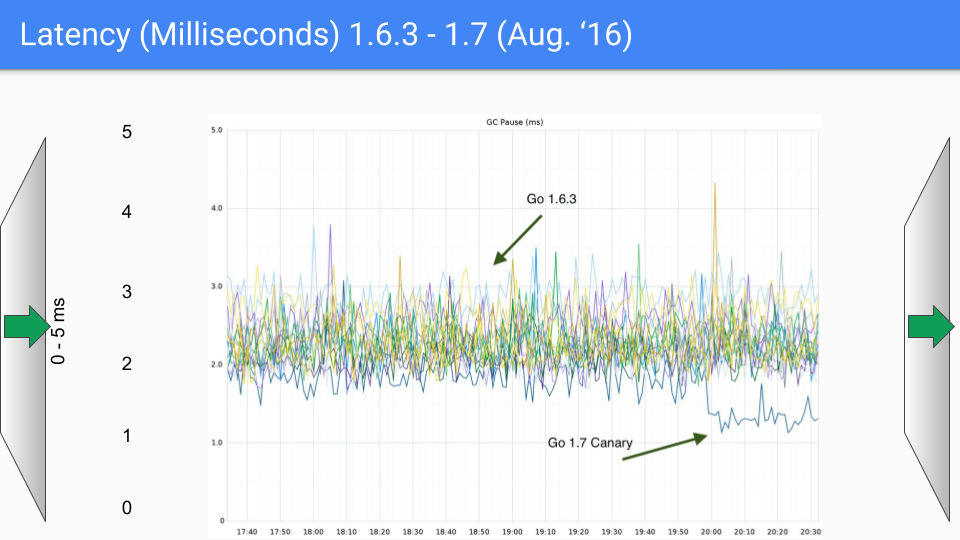
所以,你看,這是 2016 年 8 月,距離第一個版本釋出一年。我們繼續努力消除這些 O(heap size) 的“停止世界”過程。我們討論的是一個 18GB 的堆。我們有更大的堆,當我們消除了這些 O(heap size) 的“停止世界”暫停時,堆的大小顯然可以顯著增長而不影響延遲。所以這對 1.7 版本有所幫助。

下一個版本是 2017 年 3 月。我們實現了最後一個大幅度降低延遲的改進,這得益於我們找到了如何在 GC 週期結束時避免“停止世界”棧掃描的方法。這使我們的延遲降低到亞毫秒級別。再次,Y 軸將改為 1.5 毫秒,我們看到了第三次數量級改進。
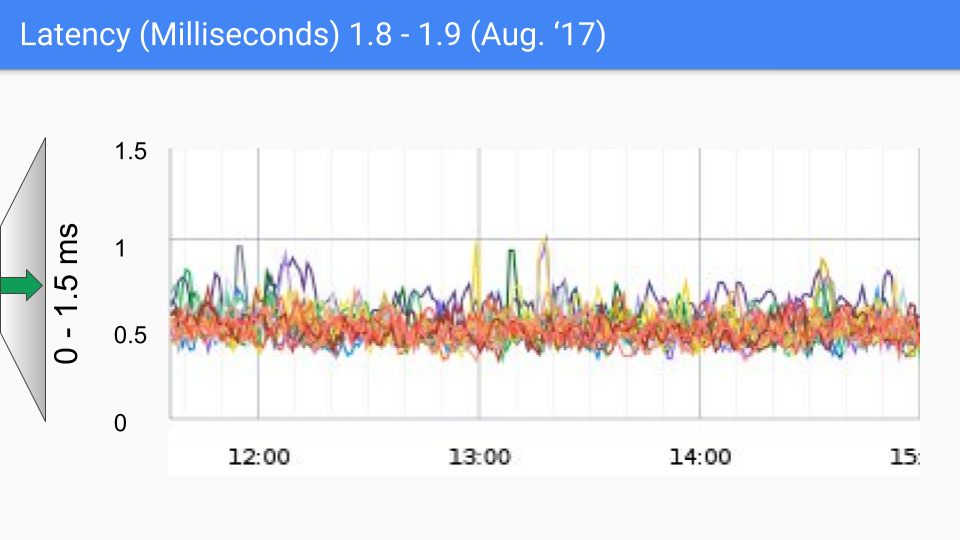
2017 年 8 月的版本改進不大。我們知道導致剩餘暫停的原因。SLO 的“耳語數”(whisper number)約為 100-200 微秒,我們將朝著這個目標努力。如果您看到任何超過幾百微秒的情況,我們真的很想和您談談,看看它是否屬於我們已知的情況,或者是否是我們尚未研究過的新情況。無論如何,似乎對更低延遲的需求不大。需要注意的是,這些延遲級別可能是由各種非 GC 原因引起的,正如俗話所說:“你不必比熊跑得快,你只需要比你旁邊的人跑得快。”
2018 年 2 月的 1.10 版本沒有實質性變化,只是進行了一些清理和處理了邊緣情況。

新的一年,新的 SLO。這是我們的 2018 年 SLO。
我們已經將 GC 週期內使用的總 CPU 降低了。
堆的大小仍然是 2 倍。
我們現在有一個目標,即每個 GC 週期“停止世界”暫停時間為 500 微秒。可能還有一點保守。
分配將繼續與 GC 輔助成正比。
Pacer 已經大大改進,因此我們在穩定狀態下看到了最小的 GC 輔助。
我們對此相當滿意。再次強調,這不是 SLA 而是 SLO,所以這是一個目標,而不是協議,因為我們無法控制作業系統等因素。

以上是好訊息。現在讓我們轉向並談談我們的失敗。這些是我們的傷疤;它們有點像紋身,每個人都有。總之,它們帶來更好的故事,所以讓我們講講這些故事。

我們的第一次嘗試是所謂的請求導向收集器 (ROC)。假設可以在此處看到。

那麼這意味著什麼?
Goroutines 是輕量級執行緒,看起來像 Gophers,所以這裡有兩個 Goroutines。它們共享一些東西,比如中間的兩個藍色物件。它們有自己的私有棧和私有物件的選擇。假設左邊的人想共享綠色物件。
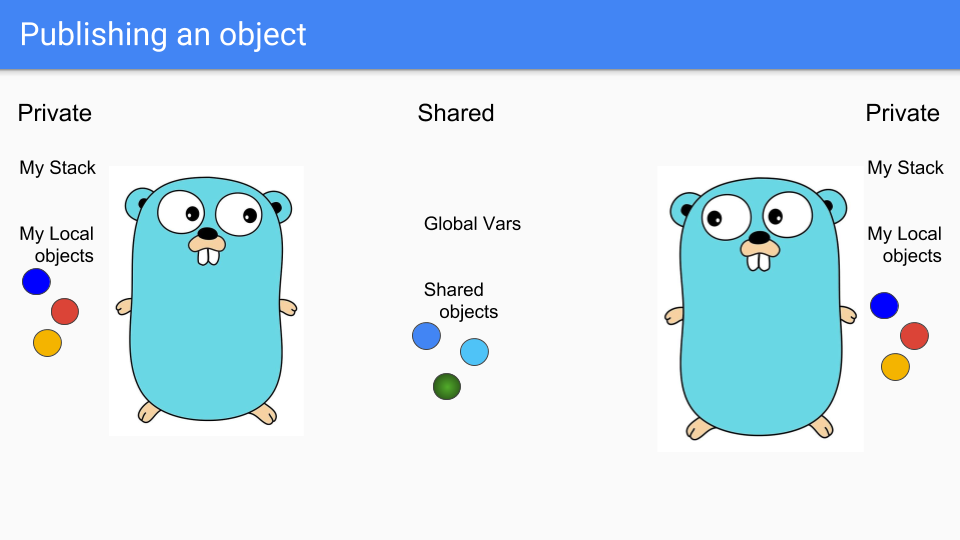
Goroutine 將其放入共享區域,以便另一個 Goroutine 可以訪問它。他們可以將其掛載到共享堆中的某個物件,或者將其分配給全域性變數,另一個 Goroutine 就可以看到它。

最後,左邊的 Goroutine 即將消亡,可悲。
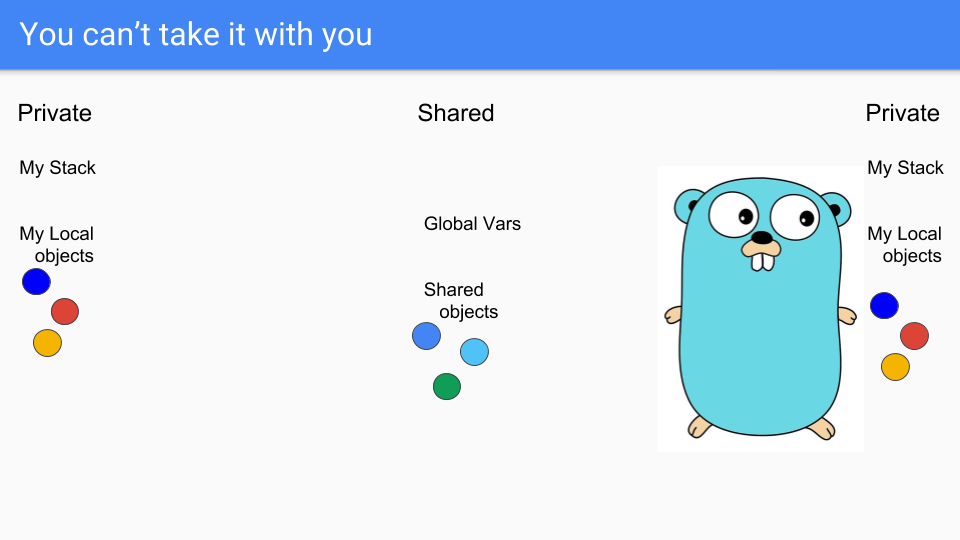
正如你所知,你不能帶著你的物件一起死去。你也不能帶走你的棧。棧此時實際上是空的,物件是不可達的,所以你可以簡單地回收它們。

這裡重要的是,所有操作都是區域性的,不需要任何全域性同步。這與分代 GC 等方法根本不同,希望我們從中獲得的擴充套件性將足以讓我們獲勝。

這個系統還存在的另一個問題是寫屏障始終處於開啟狀態。每當發生寫入時,我們就必須檢視它是否將私有物件的指標寫入了公共物件。如果是,我們就必須將所指物件設為公共,然後進行可達物件的傳遞式遍歷,確保它們也都是公共的。這是一個相當昂貴的寫屏障,可能導致許多快取未命中。
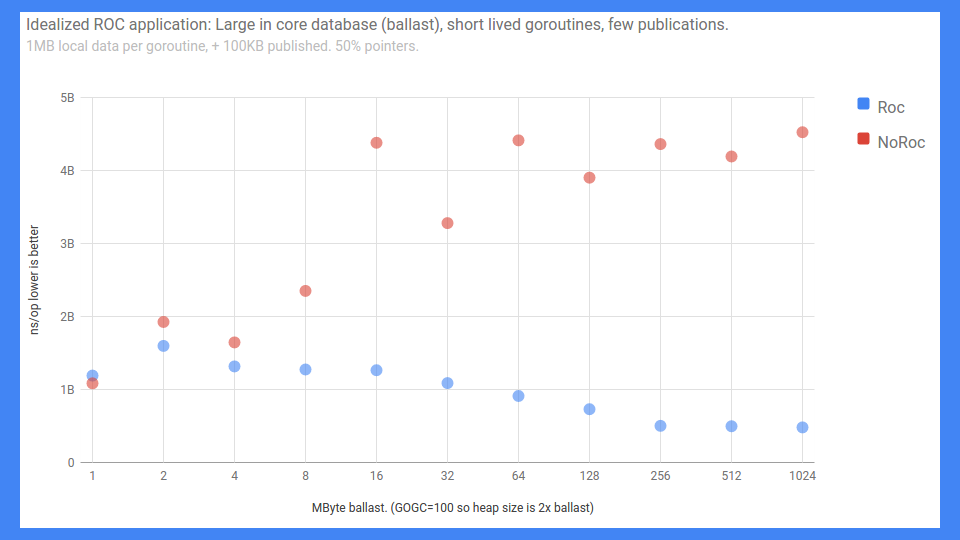
儘管如此,我們取得了一些相當不錯的成功。
這是一個端到端的 RPC 基準測試。錯誤標記的 Y 軸從 0 到 5 毫秒(越低越好),無論如何,這就是它。X 軸基本上是負載或記憶體中資料庫的大小。
正如你所見,如果啟用 ROC 且共享不多,情況會很好地擴充套件。如果不啟用 ROC,效果就沒那麼好。
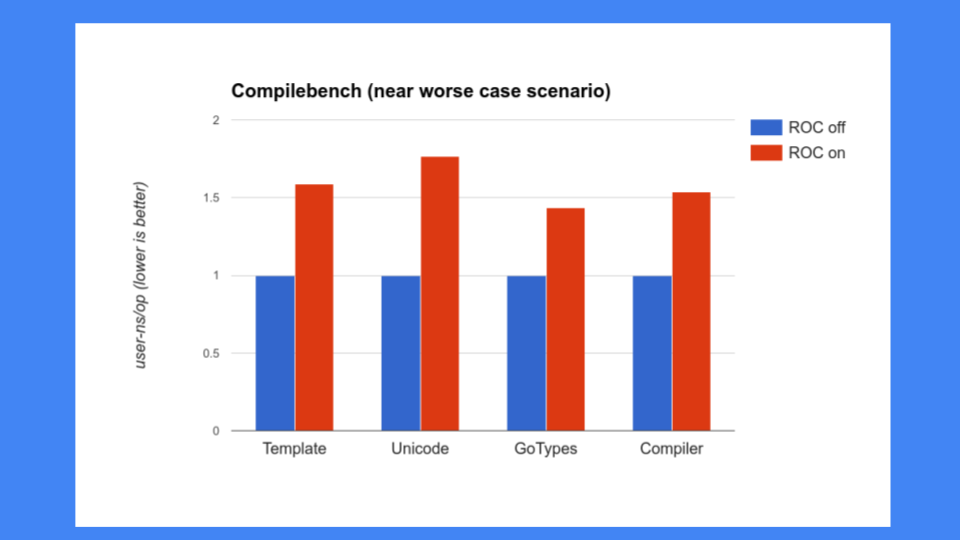
但這還不夠好,我們還必須確保 ROC 不會減慢系統的其他部分。當時人們對我們的編譯器非常關注,我們不能減慢編譯器的速度。不幸的是,編譯器恰恰是 ROC 表現不佳的程式。我們看到了 30%、40%、50% 甚至更高的效能下降,這是不可接受的。Go 以其快速的編譯器而自豪,所以我們不能讓編譯器減慢速度,尤其是不能這麼慢。
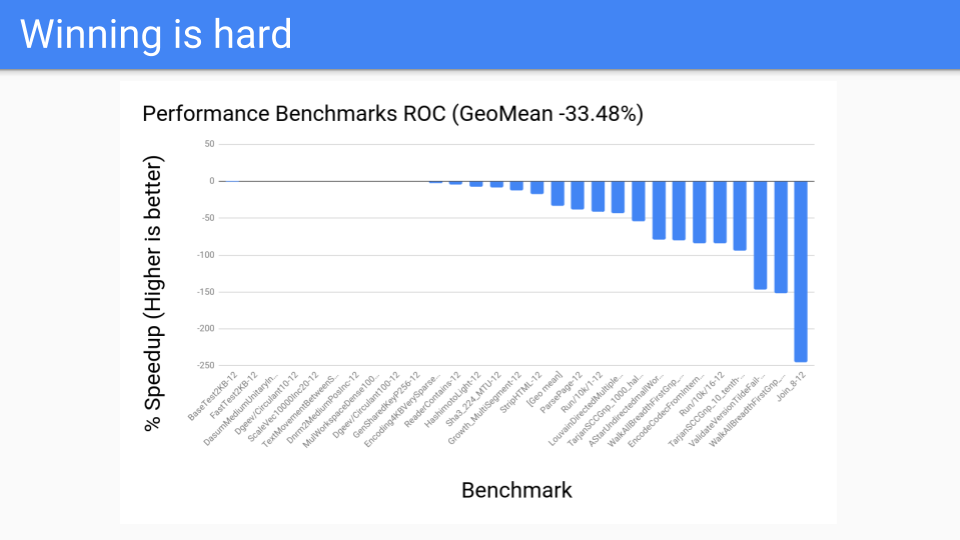
然後我們又看了一些其他程式。這些是我們的效能基準測試。我們有 200 到 300 個基準測試的語料庫,這些是編譯器人員決定對他們來說重要的改進。這些都不是 GC 人員選擇的。結果普遍不好,ROC 不會成為贏家。

的確,我們進行了擴充套件,但我們只有 4 到 12 個硬體執行緒系統,所以我們無法克服寫屏障的開銷。也許將來當我們擁有 128 核系統並得到 Go 的利用時,ROC 的擴充套件性可能會成為優勢。到那時,我們可能會重新審視,但目前 ROC 是一個失敗的提議。

那麼我們接下來要做什麼?試試分代 GC。這是一個老套但經典的辦法。ROC 行不通,所以讓我們回到我們更有經驗的東西上。

我們不會放棄我們的延遲,也不會放棄我們是非移動的事實。所以我們需要一個非移動的分代 GC。
那麼我們能做到嗎?是的,但對於分代 GC,寫屏障始終開啟。當 GC 週期執行時,我們使用與今天相同的寫屏障,但在 GC 關閉時,我們使用一個快速的 GC 寫屏障,它緩衝指標,並在緩衝區溢位時將其重新整理到卡片標記表(card mark table)。
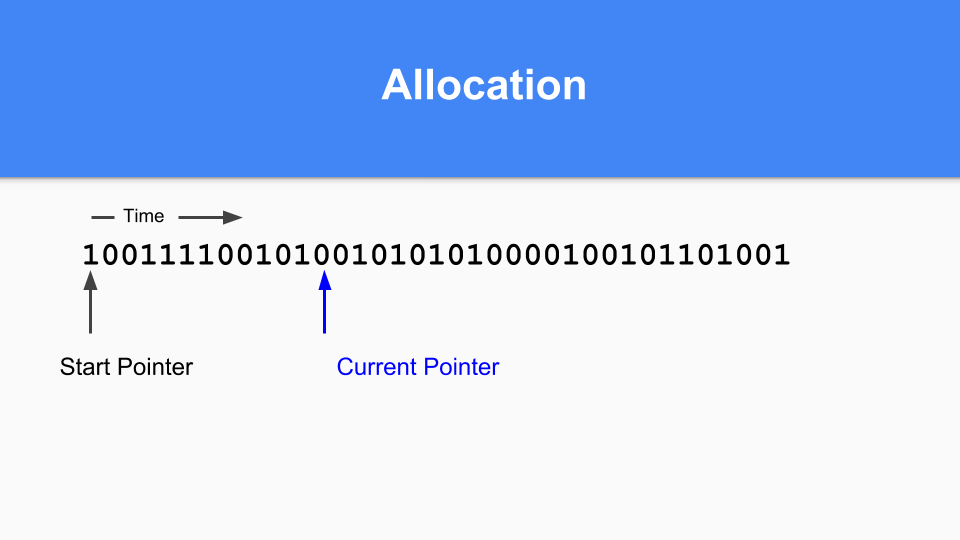
那麼在非移動的情況下它將如何工作?這是標記/分配對映。基本上,您維護一個當前指標。當您進行分配時,您會尋找下一個零,找到零後,您就在該空間中分配一個物件。
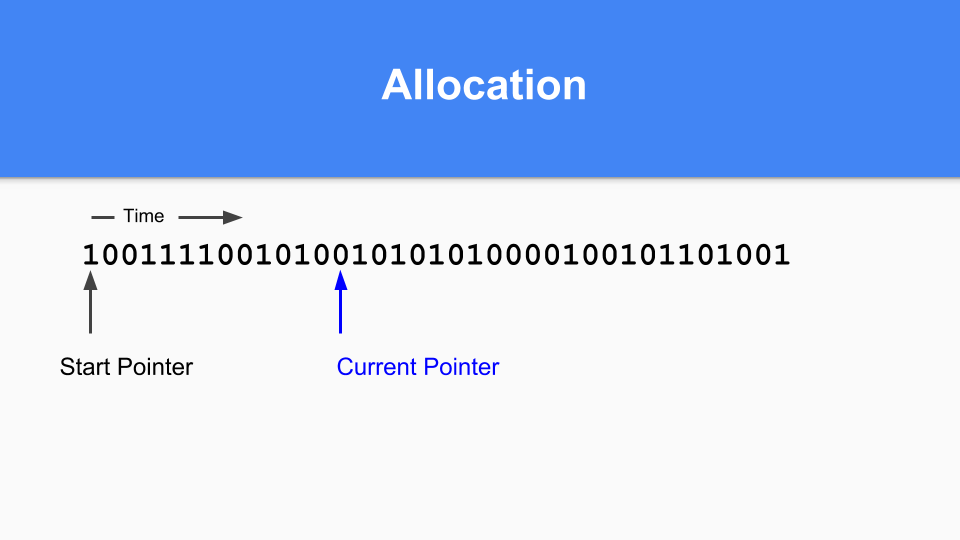
然後更新當前指標指向下一個零。

繼續進行,直到某個時候是時候進行代際 GC 了。您會注意到,如果標記/分配向量中有 1,則該物件在上次 GC 時是活動的,因此它是成熟的。如果它是零並且您訪問到它,那麼您就知道它是年輕的。
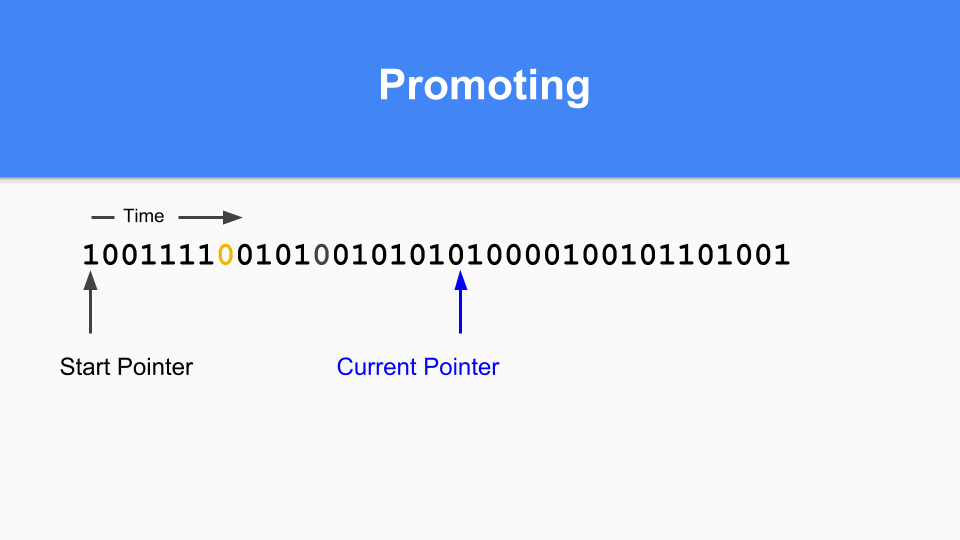
那麼如何進行提升(promoting)呢?如果您發現標記為 1 的物件指向標記為 0 的物件,那麼您只需將該零更改為 1 來提升被指向的物件。
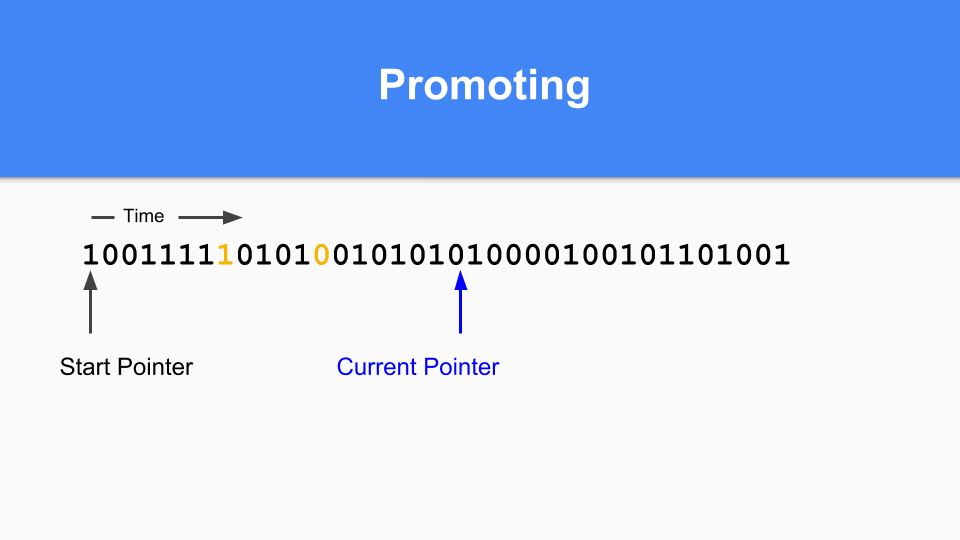
您必須進行傳遞式遍歷以確保所有可達物件都被提升。
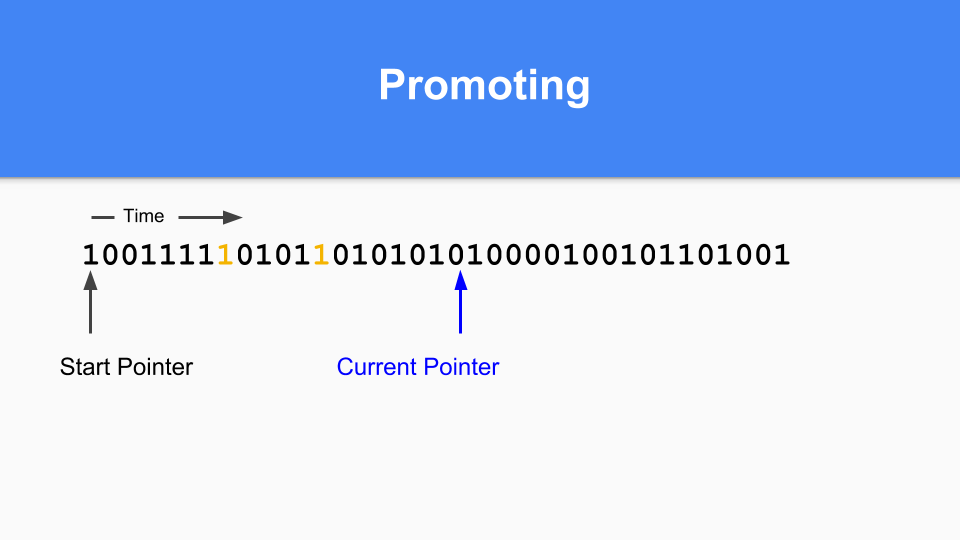
當所有可達物件都被提升後,次要 GC 終止。

最後,要完成您的分代 GC 週期,只需將當前指標重置迴向量的開頭,然後繼續。所有未被該 GC 週期訪問的零都將被釋放並可重用。正如你們中的許多人所知,這被稱為“粘性位”(sticky bits),是由 Hans Boehm 和他的同事發明的。
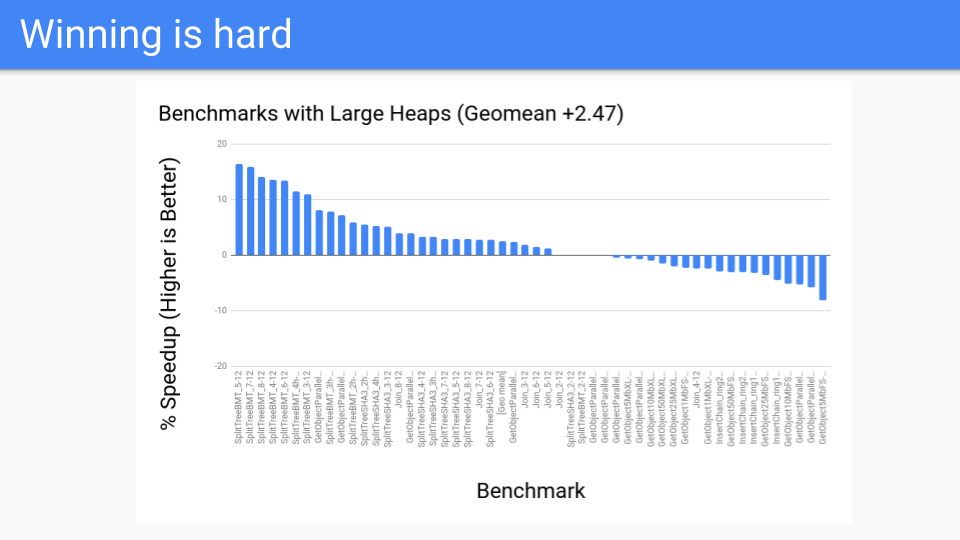
那麼效能如何?對於大堆來說還不錯。這些是 GC 應該表現良好的基準測試。這一切都很好。
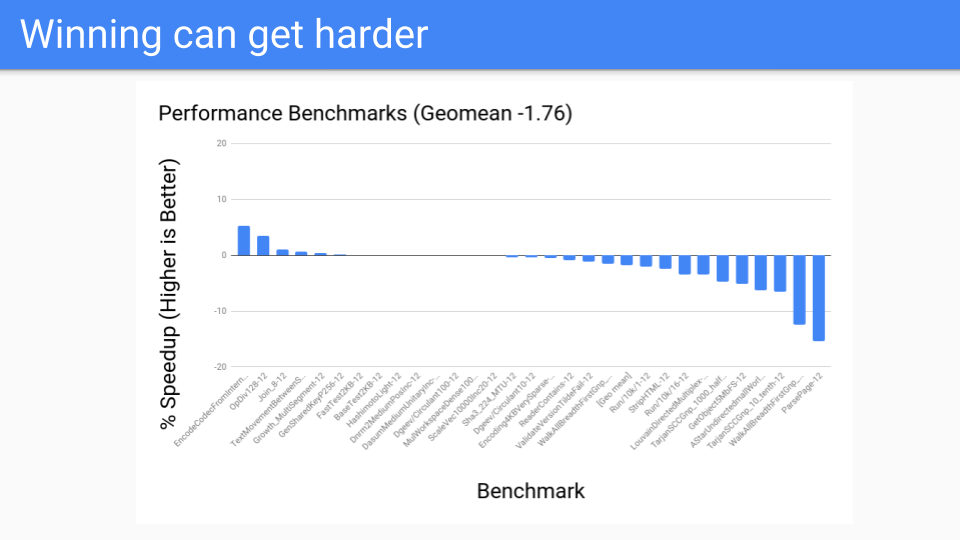
然後我們在效能基準測試上進行了測試,結果並不理想。那麼發生了什麼?

寫屏障是快速的,但仍然不夠快。而且很難對其進行最佳化。例如,如果物件分配和下一個安全點之間有初始化寫入,就可以進行寫屏障的省略。但我們必須轉向一個系統,在這個系統中,每個指令都有一個 GC 安全點,所以將來沒有任何寫屏障可以被省略。

我們還有逃逸分析(escape analysis),它越來越好。還記得我們談到的面向值的東西嗎?我們傳遞實際值而不是函式指標。由於我們傳遞的是值,逃逸分析只需要進行過程內逃逸分析(intraprocedural escape analysis),而不是過程間逃逸分析(interprocedural analysis)。
當然,在區域性物件指標逃逸的情況下,物件將被分配到堆上。
並不是說分代假設對 Go 不成立,只是年輕的物件在棧上存活和死亡。結果是,分代收集的效果不如在其他託管執行時語言中看到的。

因此,這些針對寫屏障的阻力開始聚集。今天,我們的編譯器比 2014 年好得多。逃逸分析捕獲了許多物件並將它們放在棧上——這些物件是分代收集器本可以提供幫助的物件。我們開始建立工具來幫助使用者查詢逃逸的物件,如果只是小問題,他們可以修改程式碼並幫助編譯器在棧上進行分配。
使用者越來越聰明地擁抱面向值的方法,指標數量正在減少。陣列和對映儲存值而不是指向結構體的指標。一切都很好。
但這並不是寫屏障在 Go 中面臨長期挑戰的主要令人信服的原因。
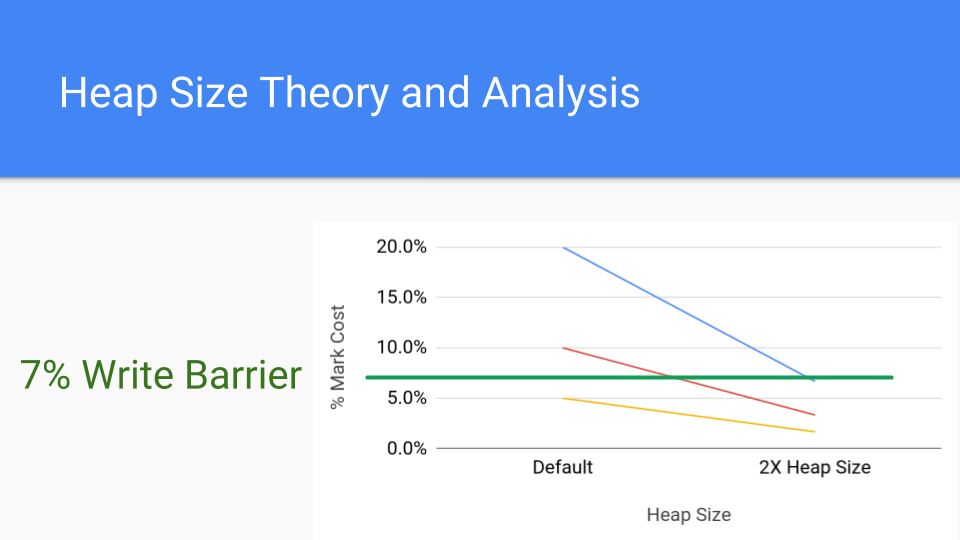
讓我們看看這張圖。這是一張標記成本的分析圖。每條線代表一種可能的標記成本不同的應用程式。假設您的標記成本為 20%,這相當高,但有可能。紅線是 10%,仍然很高。較低的線是 5%,這大約是目前寫屏障的成本。那麼,如果將堆大小加倍會怎樣?那就是右邊的點。標記階段的累積成本會大大降低,因為 GC 週期不那麼頻繁了。寫屏障成本是恆定的,所以增加堆大小的成本將使標記成本低於寫屏障的成本。
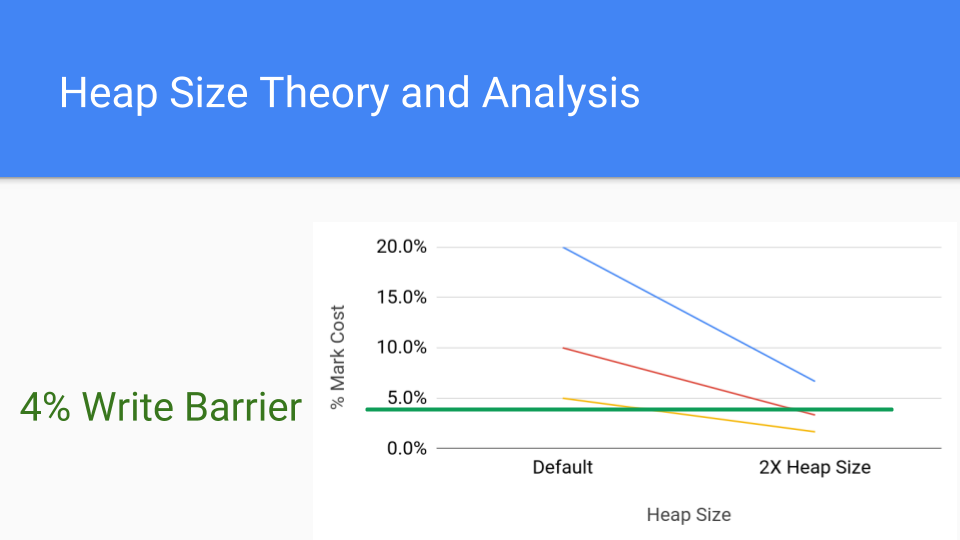
這裡是寫屏障更常見的成本,即 4%,我們看到即使有了這個成本,透過簡單地增加堆大小,也可以將標記屏障的成本降低到寫屏障成本之下。
分代 GC 的真正價值在於,在檢視 GC 時間時,寫屏障的成本被忽略了,因為它們被分散到變異器中。這是分代 GC 的主要優勢,它大大減少了完整 GC 週期的長時間 STW 時間,但並不一定能提高吞吐量。Go 沒有這個問題,所以它必須更仔細地關注吞吐量問題,而這正是我們所做的。

這有很多失敗,失敗帶來了食物和午餐。我正在進行我一貫的抱怨:“如果不是寫屏障,這該多好啊。”
與此同時,Austin 剛剛花了一個小時與谷歌的一些硬體 GC 人員交談,他建議我們與他們聯絡,看看如何獲得硬體 GC 支援可能會有幫助。然後我開始講起零填充快取行、可重啟原子序列等零碎故事,這些在我為一家大型硬體公司工作時並沒有奏效。我們確實在名為 Itanium 的晶片中實現了一些東西,但我們無法將其應用到如今更受歡迎的晶片中。所以這個故事的寓意很簡單:利用我們擁有的硬體。
總之,這讓我們開始討論,有沒有什麼瘋狂的想法?

不用寫屏障的卡片標記(card marking)怎麼樣?事實證明,Austin 有這些檔案,他把所有瘋狂的想法都寫在這些檔案裡,但不知何故他沒有告訴我。我猜這是一種治療方式。我以前和 Eliot 也是這樣。新想法很容易被摧毀,需要保護它們並使其更強大,然後再讓它們走向世界。不過,他提出了這個想法。
這個想法是,您在每個卡片中維護一個成熟指標的雜湊。如果將指標寫入卡片,雜湊值將發生變化,卡片將被視為已標記。這將用雜湊的成本來替代寫屏障的成本。

但更重要的是,它與硬體相容。
今天的現代架構擁有 AES(高階加密標準)指令。其中一條指令可以執行加密級別的雜湊,透過加密級別的雜湊,如果我們遵循標準的加密策略,就不必擔心雜湊衝突。所以雜湊不會花費我們太多成本,但我們必須載入我們要雜湊的內容。幸運的是,我們是順序遍歷記憶體,所以我們獲得了非常好的記憶體和快取效能。如果您有一個 DIMM 並且訪問順序地址,那麼這就是一個勝利,因為它們比訪問隨機地址更快。硬體預取器也會啟動,這也會有所幫助。總之,我們有 50 年、60 年設計硬體來執行 Fortran、C 和 SPECint 基準測試的經驗。硬體能快速執行這類東西也就不足為奇了。
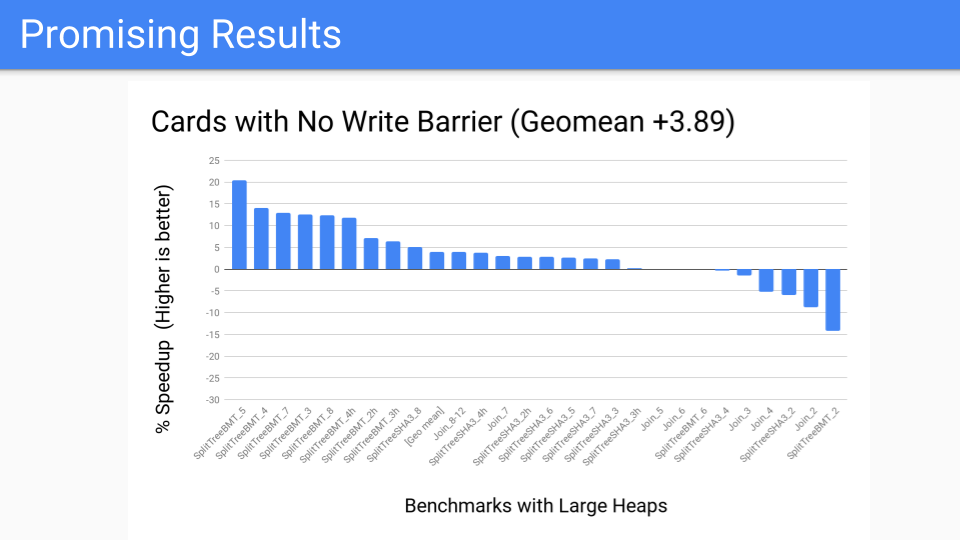
我們進行了測量。這相當不錯。這是大堆的基準測試套件,應該表現良好。
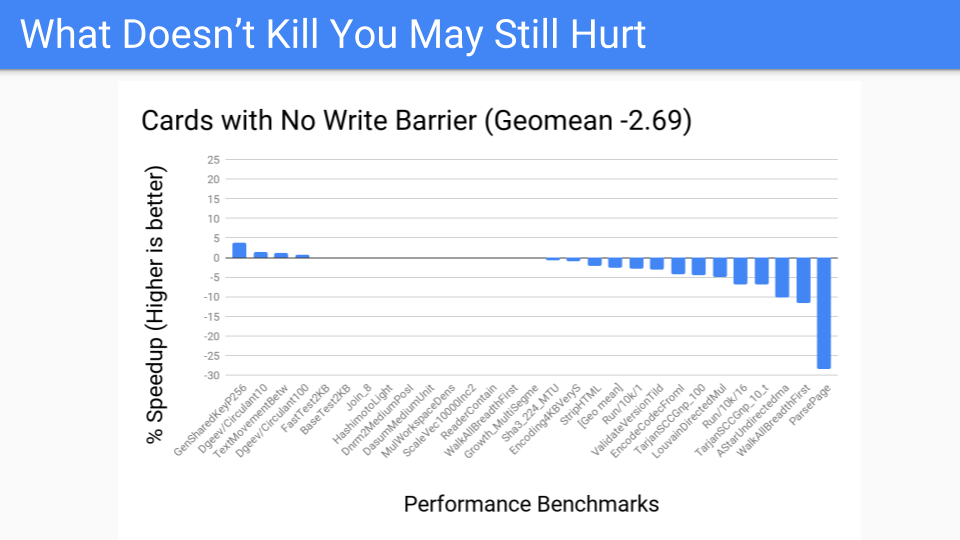
然後我們問,效能基準測試看起來怎麼樣?不太好,有幾個異常值。但現在我們已經將寫屏障從始終在變異器中開啟,轉移到作為 GC 週期的一部分執行。現在,關於是否進行分代 GC 的決定將被推遲到 GC 週期開始。我們有更多的控制權,因為我們已經將卡片工作本地化了。既然我們有了工具,就可以將其交給 Pacer,它可以很好地動態地關閉那些落在右側(不適合分代 GC)的程式。但這會贏嗎?我們必須知道,或者至少思考一下硬體未來的樣子。

未來的記憶體是什麼樣的?
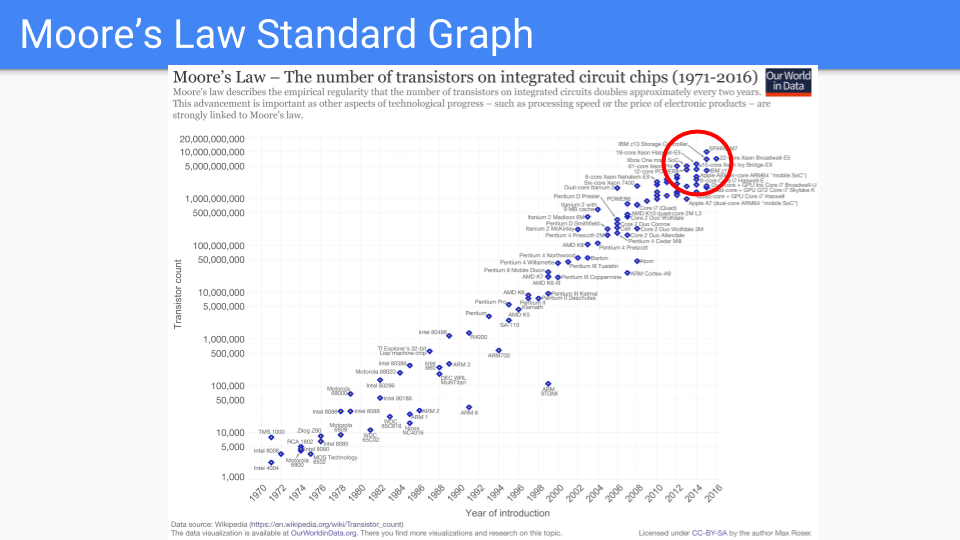
讓我們看看這張圖。這是經典的摩爾定律圖。Y 軸是晶片上的電晶體數量(對數尺度)。X 軸是 1971 年到 2016 年的年份。我注意到,這些年份是有人預測摩爾定律已死的年份。
Dennard 縮放定律大約十年前就結束了頻率改進。新工藝的爬坡時間更長。所以,從 2 年變成 4 年或更長。因此,很明顯我們正在進入摩爾定律放緩的時代。
讓我們只看紅色圓圈中的晶片。這些是他們在維持摩爾定律方面表現最好的晶片。
這些晶片的邏輯越來越簡單,並且被大量複製。大量的相同核心、多個記憶體控制器和快取、GPU、TPU 等。
隨著我們不斷簡化和增加複製,我們漸近地會得到幾根導線、一個電晶體和一個電容器。換句話說,就是 DRAM 記憶體單元。
換句話說,我們認為增加一倍記憶體的價值將大於增加一倍核心。
原始圖表 來源:www.kurzweilai.net/ask-ray-the-future-of-moores-law。

讓我們看看另一張專注於 DRAM 的圖。這些是來自卡內基梅隆大學近期博士論文的資料。如果我們看這張圖,我們會看到摩爾定律是藍線。紅線是容量,它似乎遵循摩爾定律。奇怪的是,我看到一張圖表,可以追溯到 1939 年我們還在使用鼓式儲存器,那時容量和摩爾定律就一直在同步前進,所以這張圖已經持續了很長時間,肯定比在場的大多數人都要長。
如果我們比較這張圖與 CPU 頻率或各種“摩爾定律已死”的圖表,我們會得出結論,記憶體,或者至少是晶片容量,將比 CPU 更長地遵循摩爾定律。頻寬(黃線)不僅與記憶體頻率有關,還與晶片引腳數量有關,所以它跟不上那麼好,但也不算太差。
延遲(綠線)表現非常差,儘管我注意到順序訪問的延遲比隨機訪問的延遲要好。
(資料來自“理解和改進 DRAM 記憶體系統的延遲”,部分滿足獲得電氣與計算機工程博士學位的要求,Kevin K. Chang M.S.,電氣與計算機工程,卡內基梅隆大學 B.S.,電氣與計算機工程,卡內基梅隆大學,卡內基梅隆大學,匹茲堡,PA,2017 年 5 月”。參見 Kevin K. Chang 的論文。 介紹中的原始圖表不是我能輕易繪製摩爾定律線的那種形式,所以我更改了 X 軸使其更均勻。)
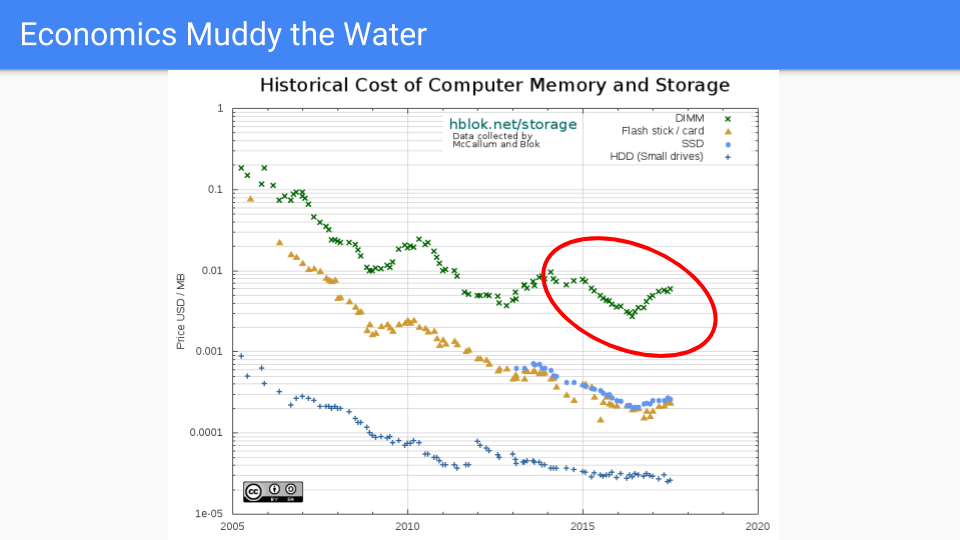
讓我們看看實際的 DRAM 定價。從 2005 年到 2016 年,價格普遍下降。我選擇 2005 年是因為大約在那時 Dennard 縮放定律結束,頻率改進也隨之結束。
如果您看看紅色圓圈,也就是我們致力於降低 Go GC 延遲的時間,我們會看到在前幾年價格表現不錯。最近,情況不太好,因為需求超過了供應,導致過去兩年價格上漲。當然,電晶體沒有變大,在某些情況下晶片容量仍在增加,所以這是市場力量驅動的。RAMBUS 和其他晶片製造商表示,到 2019-2020 年,我們將看到下一個工藝收縮。
我將避免推測記憶體行業的全球市場力量,只是指出價格是週期性的,從長遠來看,供應傾向於滿足需求。
從長遠來看,我們相信記憶體價格的下降速度將遠快於 CPU 價格。
(來源 https://hblok.net/blog/ 和 https://hblok.net/storage_data/storage_memory_prices_2005-2017-12.png)
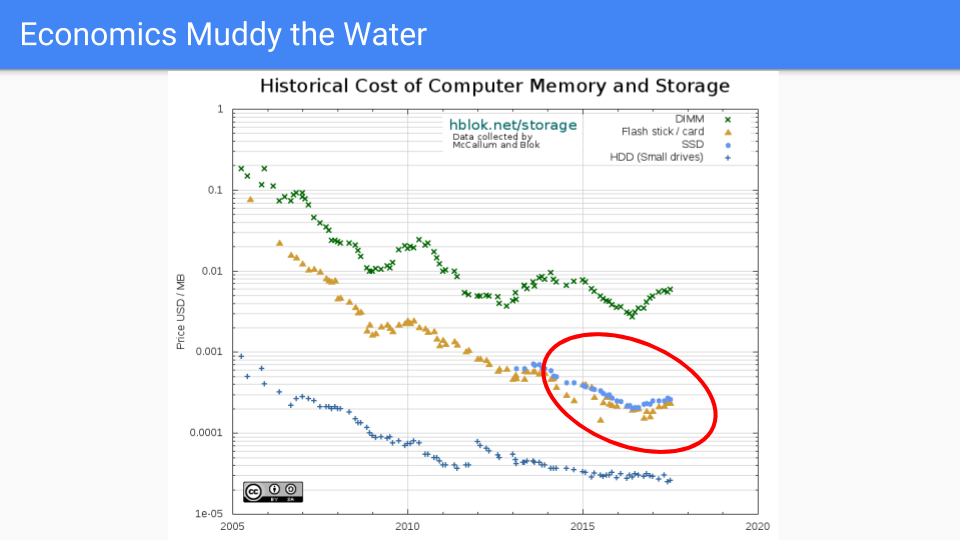
讓我們看看這條線。嗯,如果我們能在這條線上就好了。這是 SSD 線。它在保持價格低廉方面做得更好。這些晶片的材料物理學比 DRAM 更復雜。邏輯更復雜,每個單元有半打左右的電晶體,而不是一個。
未來,DRAM 和 SSD 之間將有一條線,NVRAM(如英特爾的 3D XPoint 和相變記憶體 PCM)將位於其中。在未來十年,此類記憶體的可用性增加可能會變得更加主流,這將進一步加強增加記憶體是為我們的伺服器增加價值的廉價方式這一理念。
更重要的是,我們可以期待看到其他與 DRAM 競爭的替代品。我不敢說五到十年後哪種會佔優,但競爭將非常激烈,堆記憶體將朝著我們在這裡突出顯示的藍色 SSD 線方向發展。
所有這些都強化了我們避免始終開啟的屏障而選擇增加記憶體的決定。

那麼,這一切對 Go 的未來意味著什麼?

我們打算讓執行時更加靈活和健壯,同時關注使用者反饋的邊緣情況。希望能夠收緊排程器,獲得更好的確定性和公平性,但我們不想犧牲任何效能。
我們也不打算增加 GC API 的表面積。我們已經有近十年的時間了,我們有兩個“旋鈕”,這感覺差不多。沒有一個應用程式值得我們新增新的標誌。
我們還將研究如何改進我們已經相當不錯的逃逸分析,並針對 Go 的面向值程式設計進行最佳化。不僅在程式設計方面,還在我們為使用者提供的工具方面。
在演算法上,我們將專注於那些能夠最小化屏障使用(尤其是那些始終開啟的屏障)的設計空間。
最後,也是最重要的,我們希望在未來 5 年,甚至可能 10 年裡,能夠利用摩爾定律傾向於 RAM 而非 CPU 的趨勢。
就這樣。謝謝。

附註:Go 團隊正在招聘工程師,協助開發和維護 Go 執行時和編譯器工具鏈。
感興趣嗎?請檢視我們的 空缺職位。
下一篇文章:使用 Go Cloud 進行可移植的雲程式設計
上一篇文章:更新 Go 行為準則
部落格索引