Go 部落格
邁向 Go 2
引言
[這是我今天在 Gophercon 2017 上的演講稿,旨在邀請整個 Go 社群協助我們討論和規劃 Go 2。]
2007 年 9 月 25 日,在 Rob Pike、Robert Griesemer 和 Ken Thompson 討論一種新的程式語言幾天後,Rob 提出了“Go”這個名字。

第二年,Ian Lance Taylor 和我加入了團隊,我們五人一起構建了兩個編譯器和一個標準庫,最終於 2009 年 11 月 10 日開源釋出。
在接下來的兩年裡,在新興的 Go 開源社群的幫助下,我們嘗試了大小各種的改動,完善了 Go,並於 2011 年 10 月 5 日提出了Go 1 的規劃。

在 Go 社群的更多幫助下,我們修訂並實施了該計劃,並於 2012 年 3 月 28 日釋出了 Go 1。

Go 1 的釋出標誌著近五年創意、瘋狂努力的頂峰,我們將一個名稱和一堆想法變成了一個穩定、可用於生產的語言。這也標誌著從變革和動盪轉向穩定的明確轉變。
在 Go 1 釋出之前的幾年裡,我們每週都在更改 Go,幾乎破壞了所有人的 Go 程式。我們明白這阻礙了 Go 在生產環境中的使用,因為生產環境中的程式不能每週都重寫以跟上語言的變化。正如宣佈 Go 1 的部落格文章所述,其根本驅動力在於為建立可靠的產品、專案和出版物(部落格、教程、會議演講和書籍)提供穩定的基礎,讓使用者確信他們的程式將在未來幾年內繼續編譯和執行而無需更改。
Go 1 釋出後,我們知道我們需要花時間在 Go 的設計目標——生產環境中去使用它。我們明確地從進行語言更改轉向在我們自己的專案中實際使用 Go 並改進實現:我們將 Go 移植到許多新系統,重寫了幾乎所有效能關鍵的部分以提高 Go 的執行效率,並添加了諸如競態檢測器之類的關鍵工具。
現在,我們有了五年使用 Go 構建大型、生產質量系統的經驗。我們已經對什麼有效、什麼無效有了體會。現在是時候開始 Go 演進和增長的下一步,規劃 Go 的未來了。我今天來到這裡,是想請在座的各位 Go 社群成員,無論您是在 GopherCon 的觀眾席上,還是在觀看影片,或者稍後閱讀 Go 部落格,在我們規劃和實現 Go 2 時,請與我們一起努力。
在本次演講的剩餘部分,我將解釋 Go 2 的目標;約束和限制;整體流程;撰寫我們使用 Go 的經驗的重要性,特別是它們與我們可能試圖解決的問題的關係;可能的解決方案型別;我們如何交付 Go 2;以及你們所有人如何提供幫助。
目標
我們今天對 Go 的目標與 2007 年相同。我們希望提高程式設計師在管理兩種規模方面的效率:生產規模,尤其是與許多其他伺服器互動的併發系統,如今以雲軟體為代表;以及開發規模,尤其是由許多工程師鬆散協調的大型程式碼庫,如今以現代開源開發為代表。
這些規模會在各種規模的公司中出現。即使是一家五人的初創公司,也可能使用其他公司提供的龐大的基於雲的 API 服務,並使用比自己編寫的軟體更多的開源軟體。生產規模和開發規模對於這家初創公司來說,與在 Google 一樣重要。
Go 2 的目標是解決 Go 在規模化方面最顯著的不足之處。
(關於這些目標的更多資訊,請參閱 Rob Pike 2012 年的文章“Go at Google: Language Design in the Service of Software Engineering”和我 2015 年 GopherCon 的演講“Go, Open Source, Community”。)
約束
Go 的目標自始至終未變,但 Go 的約束條件肯定已經改變。最重要的約束是現有的 Go 用法。我們估計全球有至少五十萬 Go 開發者,這意味著有數百萬個 Go 原始檔和至少十億行 Go 程式碼。這些程式設計師和原始碼代表了 Go 的成功,但它們也是 Go 2 的主要約束。
Go 2 必須能夠相容所有這些開發者。我們必須要求他們放棄舊習慣、學習新習慣,但前提是回報巨大。例如,在 Go 1 之前,錯誤型別實現的方法名為 String。在 Go 1 中,我們將其重新命名為 Error,以區分錯誤型別和其他可以自我格式化的型別。前幾天我在實現一個錯誤型別時,不假思索地將其方法命名為 String 而不是 Error,這當然無法編譯。五年後,我還沒有完全改掉舊習慣。這種澄清性的重新命名是 Go 1 中一個重要的改變,但如果沒有非常充分的理由,對 Go 2 來說過於顛覆。
Go 2 還必須相容所有現有的 Go 1 原始碼。我們絕不能分裂 Go 生態系統。混合程式,即 Go 2 編寫的包匯入 Go 1 編寫的包,反之亦然,在長達數年的過渡期內必須無縫工作。我們將不得不弄清楚具體如何做到這一點;像 go fix 這樣的自動化工具肯定會發揮作用。
為了最大限度地減少干擾,每個更改都需要仔細思考、規劃和工具支援,這反過來又限制了我們可以進行的更改數量。也許我們可以做兩三個,肯定不會超過五個。
我不包括小的維護性更改,例如允許更多口語化語言中的識別符號或新增二進位制整數文字。這些小的更改也很重要,但更容易正確實現。我今天關注的是可能發生的重大更改,例如對錯誤處理的額外支援,或者引入不可變或只讀值,或者新增某種形式的泛型,或其他尚未提出的重要主題。我們只能做其中少數重大更改。我們將不得不謹慎選擇。
流程
這就引出了一個重要問題。開發 Go 的流程是什麼?
在 Go 的早期,只有我們五個人時,我們在一對相鄰的共享辦公室裡工作,中間隔著一扇玻璃牆。很容易把每個人都叫到一個辦公室討論某個問題,然後回到各自的工位實現解決方案。在實現過程中出現一些曲折時,很容易再次召集大家。Rob 和 Robert 的辦公室裡有一個小沙發和一個白板,所以通常我們會有人進去在白板上寫一個例子。通常等例子寫完時,其他人也都在自己的工作中找到了合適的停頓點,準備坐下來討論。這種非正式的溝通方式顯然無法適應如今全球化的 Go 社群。
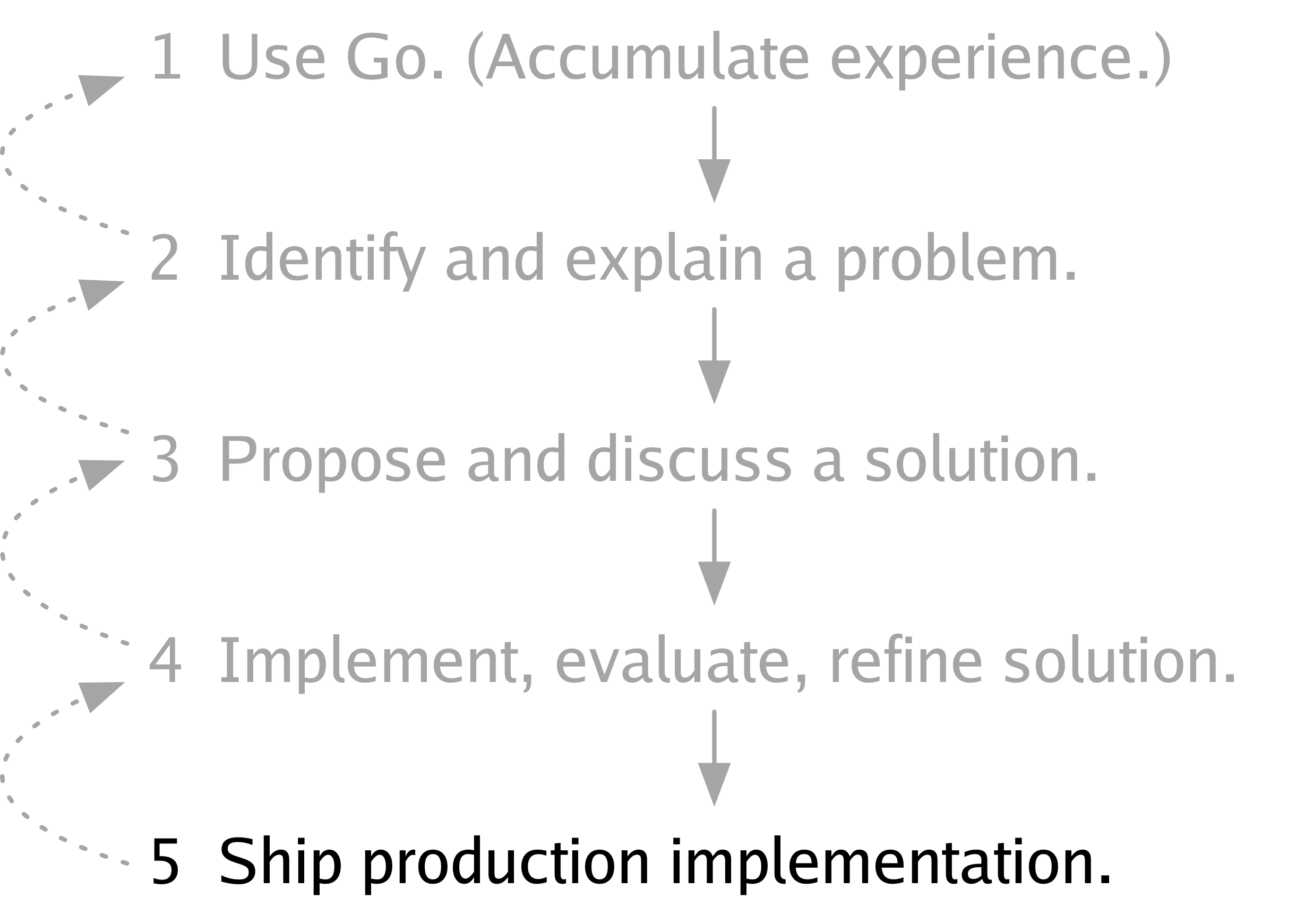
自 Go 開源釋出以來,我們的一部分工作就是將我們的非正式流程移植到更正式的郵件列表、問題跟蹤器和五十萬使用者環境中,但我認為我們從未明確描述過我們的整體流程。有可能我們從未有意識地考慮過它。然而,回顧過去,我認為這是我們 Go 工作的基本框架,是我們自第一個原型執行以來一直遵循的流程。
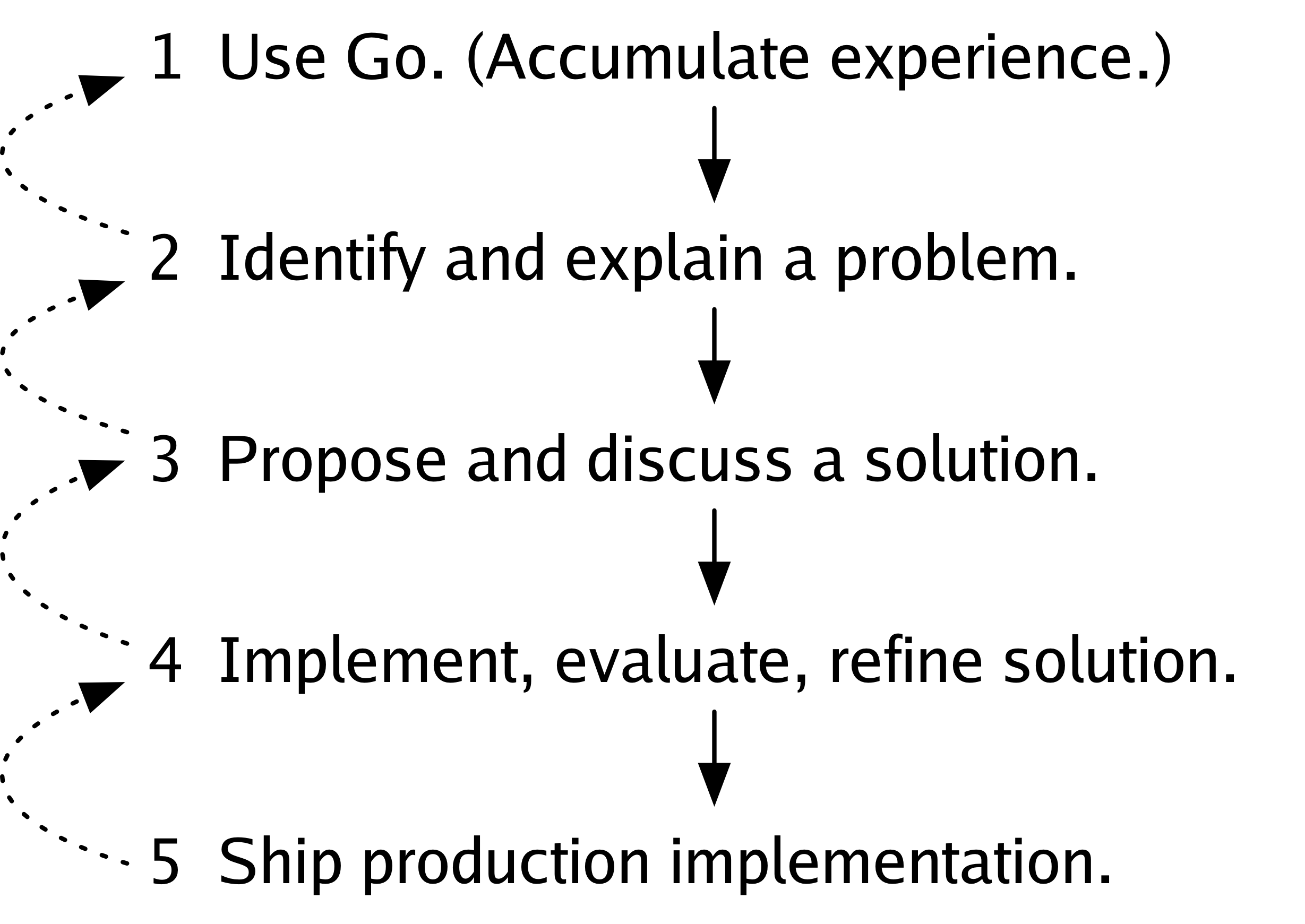
第一步是使用 Go,積累使用經驗。
第二步是識別 Go 中可能需要解決的問題並將其闡明,向他人解釋,寫下來。
第三步是提出問題的解決方案,與他人討論,並根據討論修改解決方案。
第四步是實現解決方案,評估它,並根據評估進行改進。
最後,第五步是交付解決方案,將其新增到語言、庫或人們日常使用的工具集中。
對於一個特定的更改,不必由同一個人完成所有這些步驟。事實上,通常有許多人合作完成任何一個步驟,並且可能為同一個問題提出許多解決方案。此外,在任何時候,我們都可能意識到我們不想繼續推進某個想法,並回到前面的步驟。
雖然我認為我們從未將這個流程作為一個整體來談論過,但我們解釋過其中的一部分。2012 年,當我們釋出 Go 1 並說現在是時候使用 Go 而不是更改它時,我們是在解釋第一步。2015 年,當我們引入 Go 更改提案流程時,我們是在解釋第三、第四和第五步。但我們從未詳細解釋過第二步,所以我想現在來做這件事。
(關於 Go 1 的開發以及從語言更改轉向其他方面的更多資訊,請參閱 Rob Pike 和 Andrew Gerrand 2012 年 OSCON 的演講“The Path to Go 1”。關於提案流程的更多資訊,請參閱 Andrew Gerrand 2015 年 GopherCon 的演講“How Go was Made”以及提案流程文件。)
解釋問題
解釋問題有兩個部分。第一部分——也是比較容易的部分——是準確說明問題是什麼。我們開發者在這方面做得相當好。畢竟,我們寫的每一個測試都是一個需要解決的問題的陳述,語言精確到連計算機都能理解。第二部分——也是比較難的部分——是充分描述問題的意義,以便每個人都能理解為什麼我們應該花時間解決它並維護解決方案。與精確陳述問題不同,我們不需要經常描述問題的意義,而且我們在這方面做得遠不如在陳述問題上。計算機從不問我們“這個測試用例為什麼重要?你確定這就是你需要解決的問題嗎?解決這個問題是你現在能做的最重要的事情嗎?”也許有一天會的,但不是今天。
讓我們來看一個 2011 年的舊例子。這是我在規劃 Go 1 時寫下關於將 os.Error 重新命名為 error.Value 的內容。

它以一個精確的、單行的陳述開始:在非常底層的庫中,所有東西都匯入“os”來使用 os.Error。然後有五行,我在這裡用下劃線標出,用於描述問題的意義:被“os”使用的包無法在自己的 API 中呈現錯誤,而其他包依賴“os”的原因與作業系統服務無關。
這五行話能讓你相信這個問題很重要嗎?這取決於你能多好地填補我省略的上下文:被理解需要預測他人需要知道什麼。對我當時的目標受眾——在 Google 閱讀該文件的另外十位 Go 團隊成員——來說,這五十個詞就足夠了。為了將同樣的問題呈現給去年秋天 GothamGo 的觀眾——一個背景和專業領域更加多樣化的觀眾——我需要提供更多的上下文,我使用了大約兩百個詞,加上真實的程式碼示例和圖表。當今全球化的 Go 社群的一個事實是,描述任何問題的意義都需要新增上下文,特別是透過具體的例子來說明,而當你與同事交談時,你會省略這些。
說服他人問題的重要性是一個至關重要的步驟。當一個問題顯得微不足道時,幾乎所有解決方案都會顯得過於昂貴。但對於一個重要的問題,通常有很多成本合理的解決方案。當我們不同意採納某個特定解決方案時,我們實際上可能是在不同意所解決問題的意義。這一點非常重要,我想回顧兩個最近的例子,至少事後看來,它們清晰地展示了這一點。
示例:閏秒
我的第一個例子是關於時間的。
假設你想測量一個事件需要多長時間。你記下開始時間,執行事件,記下結束時間,然後從結束時間中減去開始時間。如果事件持續了十毫秒,減法的結果就是十毫秒,可能加上或減去一個小的測量誤差。
start := time.Now() // 3:04:05.000
event()
end := time.Now() // 3:04:05.010
elapsed := end.Sub(start) // 10 ms
這種明顯的程式在閏秒期間會失敗。當我們的時鐘與地球的每日自轉不太同步時,會在午夜前插入一個閏秒——正式為晚上 11:59 和 60 秒。與閏年不同,閏秒沒有可預測的模式,這使得它們難以融入程式和 API。作業系統通常透過在午夜前將時鐘回撥一秒來實現閏秒,而不是試圖表示偶爾出現的 61 秒分鐘,這樣晚上 11:59 和 59 秒就會出現兩次。這個時鐘重置使得時間看起來是倒退的,所以我們十毫秒的事件可能會被計時為負 990 毫秒。
start := time.Now() // 11:59:59.995
event()
end := time.Now() // 11:59:59.005 (really 11:59:60.005)
elapsed := end.Sub(start) // –990 ms
由於日時鐘在這樣的時鐘重置期間不適用於計時事件,作業系統現在提供第二個時鐘,即單調時鐘,它沒有絕對意義但會計算秒數且永不重置。
除了奇數次時鐘重置之外,單調時鐘並不比日時鐘好,而日時鐘的好處是它有助於報時,所以為了簡潔起見,Go 1 的時間 API 只暴露了日時鐘。
2015 年 10 月,一個bug 報告指出,Go 程式無法在時鐘重置(尤其是典型的閏秒)期間正確計時事件。建議的修復也是最初的 issue 標題:“新增一個新的 API 來訪問單調時鐘源”。我爭辯說,這個問題不夠重要,不值得新增 API。幾個月前,對於 2015 年中期的閏秒,Akamai、Amazon 和 Google 在一整天內都微調了時鐘,用平滑的方式吸收了額外的一秒,而沒有回撥時鐘。這似乎預示著這種“閏秒平滑”方法的最終廣泛採用將消除閏秒時鐘重置作為生產系統上的問題。相比之下,在 Go 中新增新 API 會帶來新問題:我們需要解釋兩種時鐘,教育使用者何時使用哪種時鐘,以及轉換許多現有的程式碼行,這一切都是為了一個很少發生且可能自行消失的問題。
當出現沒有明確解決方案的問題時,我們總是那樣做:等待。等待讓我們有更多時間來積累經驗和理解問題,也有更多時間找到一個好的解決方案。在這種情況下,等待增加了我們對問題重要性的理解,形式是一次幸運地微小的Cloudflare 的故障。他們的 Go 程式碼將 2016 年末閏秒期間的 DNS 請求計時為大約負 990 毫秒,導致其伺服器同時發生恐慌,在高峰期中斷了 0.2% 的 DNS 查詢。
Cloudflare 正是 Go 所針對的那種雲系統,而且由於 Go 無法正確計時事件而導致了生產故障。然後,關鍵在於,Cloudflare 在一篇題為“How and why the leap second affected Cloudflare DNS”的部落格文章中報告了他們的經驗。透過分享他們在生產環境中 Go 使用的具體細節,John 和 Cloudflare 幫助我們理解了,準確計時跨閏秒時鐘重置的問題過於重要,不能置之不理。在那篇文章釋出兩個月後,我們設計並實現了一個解決方案,該解決方案將在 Go 1.9 中釋出(實際上,我們是沒有新增 API 完成的)。
示例:別名宣告
我的第二個例子是 Go 對別名宣告的支援。
在過去的幾年裡,Google 成立了一個專注於大規模程式碼更改的團隊,意味著 API 遷移和 Bug 修復應用於我們用 C++、Go、Java、Python 等語言編寫的數百萬原始檔和數十億行程式碼的程式碼庫。我從該團隊的工作中學到的一件事是,當將 API 從一個名稱更改為另一個名稱時,能夠分多步更新客戶端程式碼,而不是一次性完成,這一點非常重要。要做到這一點,必須能夠編寫一個宣告,將對舊名稱的使用轉發到新名稱。C++ 有 #define、typedef 和 using 宣告來實現這種轉發,但 Go 沒有。當然,Go 的目標之一是能夠很好地擴充套件到大型程式碼庫,隨著 Google 中 Go 程式碼量的增長,變得很清楚我們需要某種形式的轉發機制,並且其他專案和公司也會在它們的 Go 程式碼庫增長時遇到這個問題。
2016 年 3 月,我開始與 Robert Griesemer 和 Rob Pike 討論 Go 如何處理漸進式程式碼庫更新,我們得出了別名宣告,它們正是所需的轉發機制。此時,我對 Go 的發展方向感覺非常好。我們從 Go 的早期就開始討論別名——事實上,第一個規範草案中有一個使用別名宣告的例子——但每次我們討論別名,以及後來的類型別名時,我們都沒有明確的用例,所以我們沒有包含它們。現在我們提議新增別名,不是因為它們是一個優雅的概念,而是因為它們解決了 Go 在滿足可擴充套件軟體開發目標方面的一個重要實際問題。我希望這能為 Go 的未來變化提供一個模型。
春季晚些時候,Robert 和 Rob 編寫了提案,Robert 在 2016 年 Gophercon 的閃電演講中進行了演示。接下來的幾個月並不順利,而且絕對不是 Go 未來變化的榜樣。我們學到的許多教訓之一是描述問題的重要性。
一分鐘前,我向你們解釋了這個問題,提供了一些關於它如何產生以及為什麼產生的背景資訊,但沒有具體的例子可以幫助你們評估這個問題是否會在某個時候影響到你們。去年夏天的提案和閃電演講給出了一個抽象的例子,涉及包 C、L、L1 和 C1 到 Cn,但沒有開發者可以聯絡的具體例子。結果,社群的大部分反饋都基於別名只解決了 Google 問題,而不是其他人的問題。
就像我們在 Google 最初不理解正確處理閏秒時間重置的重要性一樣,我們也未能有效地向更廣泛的 Go 社群傳達在大型程式碼更改期間處理漸進式程式碼遷移和修復的重要性。
秋天我們重新開始。我做了一個演講並寫了一篇文章,展示了這個問題,使用了來自開原始碼庫的多個具體示例,說明這個問題在何處都會出現,不僅僅是在 Google 內部。現在更多人理解了這個問題並能看到其重要性,我們進行了一次富有成效的討論,關於哪種解決方案最好。結果是類型別名將包含在 Go 1.9 中,並將有助於 Go 擴充套件到越來越大的程式碼庫。
經驗報告
這裡的教訓是,以一種在不同環境中工作的人能夠理解的方式描述問題的意義是困難但至關重要的。為了在社群中討論 Go 的重大更改,我們將需要特別關注描述我們想要解決的任何問題的意義。最清晰的方法是展示問題如何影響實際程式和實際生產系統,就像在Cloudflare 的部落格文章和我的重構文章中一樣。
像這樣的經驗報告將抽象問題轉化為具體問題,並幫助我們理解其意義。它們也充當測試用例:任何提出的解決方案都可以透過檢查它對報告所描述的實際、真實世界問題的實際影響來評估。
例如,我最近在研究泛型,但我腦海中沒有對 Go 使用者需要泛型來解決的詳細、具體問題的清晰圖景。因此,我無法回答諸如是否支援泛型方法的設計問題,即方法獨立於接收者進行引數化。如果我們有大量真實用例,我們可以透過檢查重要的用例來開始回答這樣的問題。
再舉個例子,我看到過各種擴充套件錯誤介面的提案,但我沒有看到任何經驗報告顯示大型 Go 程式如何嘗試理解和處理錯誤,更不用說顯示當前的錯誤介面如何阻礙這些嘗試了。在解決問題之前,這些報告將幫助我們所有人都更好地理解問題的細節和重要性。
我還可以繼續說下去。Go 的每一個潛在的重大更改都應該由一個或多個經驗報告來驅動,這些報告記錄了人們今天如何使用 Go 以及為什麼這不夠好。對於我們可能考慮的明顯的重大更改,我不瞭解有多少此類報告,特別是沒有用真實世界示例來說明的報告。
這些報告是 Go 2 提案流程的原材料,我們需要你們所有人來撰寫它們,以幫助我們理解你們在 Go 方面的經驗。你們有五十萬人,在各種各樣的環境中工作,而我們卻沒那麼多。在您自己的部落格上寫一篇文章,或者寫一篇Medium帖子,或者寫一個GitHub Gist(為 Markdown 新增 .md 副檔名),或者寫一個Google 文件,或者使用您喜歡的任何其他釋出機制。釋出後,請將帖子新增到我們的新 wiki 頁面 golang.org/wiki/ExperienceReports。
解決方案
既然我們知道如何識別和解釋需要解決的問題,我想簡要說明一點,並非所有問題都最好透過語言更改來解決,這沒關係。
我們可能想解決的一個問題是,計算機通常可以在基本的算術運算中計算出附加結果,但 Go 不提供對這些結果的直接訪問。2013 年,Robert 提議我們可以將雙結果(“comma-ok”)表示式的想法擴充套件到基本算術運算。例如,如果 x 和 y 是,比如說,uint32 值,lo, hi = x * y 不僅會返回通常的低 32 位,還會返回乘積的高 32 位。這個問題似乎並不特別重要,所以我們記錄了潛在的解決方案但沒有實現。我們等待著。
最近,我們為 Go 1.9 設計了一個math/bits 包,其中包含各種位操作函式
package bits // import "math/bits"
func LeadingZeros32(x uint32) int
func Len32(x uint32) int
func OnesCount32(x uint32) int
func Reverse32(x uint32) uint32
func ReverseBytes32(x uint32) uint32
func RotateLeft32(x uint32, k int) uint32
func TrailingZeros32(x uint32) int
...
該包對每個函式都有很好的 Go 實現,但編譯器也會在可用時替換特殊的硬體指令。基於 math/bits 的經驗,Robert 和我都認為透過更改語言來提供附加的算術結果是不明智的,而應該在 math/bits 這樣的包中定義適當的函式。這裡最好的解決方案是庫更改,而不是語言更改。
另一個我們可能想解決的問題是,在 Go 1.0 之後,goroutine 和共享記憶體使得在 Go 程式中引入競態變得過於容易,導致生產環境崩潰和其他行為異常。基於語言的解決方案是找到某種方法來禁止資料競態,使編寫甚至編譯一個存在資料競態的程式成為不可能。如何在像 Go 這樣的語言中實現這一點仍然是程式語言世界中的一個懸而未決的問題。相反,我們在主發行版中添加了一個工具,並使其易於使用:這個工具,即競態檢測器,已經成為 Go 體驗不可或缺的一部分。這裡最好的解決方案是執行時和工具鏈更改,而不是語言更改。
當然,也會有語言更改,但並非所有問題都最好在語言層面解決。
釋出 Go 2
最後,我們將如何釋出和交付 Go 2?
我認為最好的計劃是,將 Go 2 的向後相容部分透過 Go 1 的釋出序列,增量地、逐個功能地釋出。這有幾個重要的優點。首先,它使 Go 1 的釋出保持正常的時間表,繼續提供使用者現在依賴的及時 Bug 修復和改進。其次,它避免了在 Go 1 和 Go 2 之間分割開發精力。第三,它避免了 Go 1 和 Go 2 之間的分歧,以緩和最終的所有遷移。第四,它允許我們一次專注於一個更改並交付它,這應該有助於保持質量。第五,它將鼓勵我們設計向後相容的功能。
在任何更改開始進入 Go 1 版本之前,我們需要時間進行討論和規劃,但對我來說,似乎有可能我們在一年左右後開始看到一些小的更改,大約是 Go 1.12。這也給了我們時間先支援包管理。
一旦所有向後相容的工作完成,例如在 Go 1.20 中,我們就可以在 Go 2.0 中進行向後不相容的更改。如果最終沒有向後不相容的更改,也許我們只需宣佈 Go 1.20 就是 Go 2.0。無論哪種方式,屆時我們將從 Go 1.X 版本序列的開發過渡到 Go 2.X 序列的開發,也許為最後的 Go 1.X 版本提供一個擴充套件的支援視窗。
這一切都有些推測性,我剛才提到的具體版本號只是粗略估計的佔位符,但我想明確的是,我們不會放棄 Go 1,事實上,我們將盡可能地保留 Go 1。
尋求幫助
我們需要您的幫助。
Go 2 的對話從今天開始,將在公開場合,在郵件列表和問題跟蹤器等公共論壇上進行。請在每一步都幫助我們。
今天,我們最需要的是經驗報告。請告訴我們 Go 對您來說如何奏效,更重要的是,如何不奏效。寫一篇博文,包含真實示例、具體細節和真實經歷。並在我們的wiki 頁面上鍊接它。這就是我們將開始討論我們 Go 社群可能想改變 Go 的地方。
謝謝。
下一篇文章:貢獻者峰會
上一篇文章:引入開發者體驗工作組
部落格索引