Go 部落格
使用 Go 構建 LLM 驅動的應用程式
隨著在過去一年中,LLM(大型語言模型)及其相關工具(如嵌入模型)的功能顯著增強,越來越多的開發人員正在考慮將 LLM 整合到他們的應用程式中。
由於 LLM 通常需要專用硬體和大量的計算資源,因此它們最常被打包成提供 API 訪問的網路服務。領先的 LLM(如 OpenAI 或 Google Gemini)就是這樣工作的;即使是像 Ollama 這樣的本地 LLM 工具,也會將 LLM 包裝在 REST API 中以供本地使用。此外,在應用程式中利用 LLM 的開發人員通常還需要諸如向量資料庫之類的輔助工具,而這些工具也最常作為網路服務進行部署。
換句話說,LLM 驅動的應用程式與其他現代雲原生應用程式非常相似:它們需要對 REST 和 RPC 協議、併發性和效能有出色的支援。而這些恰恰是 Go 擅長的領域,這使其成為編寫 LLM 驅動應用程式的絕佳語言。
這篇博文將透過一個使用 Go 構建簡單 LLM 驅動應用程式的示例。它首先描述了演示應用程式正在解決的問題,然後展示了應用程式的幾個變體,它們都完成了相同的任務,但使用了不同的軟體包來實現。本文演示的所有程式碼均線上提供。
一個用於問答的 RAG 伺服器
一種常見的 LLM 驅動應用程式技術是 RAG(檢索增強生成)。RAG 是定製 LLM 知識庫以進行領域特定互動的最具可擴充套件性的方法之一。
我們將用 Go 構建一個RAG 伺服器。這是一個提供兩個操作給使用者的 HTTP 伺服器:
- 將文件新增到知識庫
- 就知識庫向 LLM 提問
在典型的實際場景中,使用者會將大量文件新增到伺服器,然後開始向其提問。例如,一家公司可以將 RAG 伺服器的知識庫填充內部文件,並利用它為內部使用者提供 LLM 驅動的問答功能。
這是展示我們的伺服器與外部世界互動的圖示:
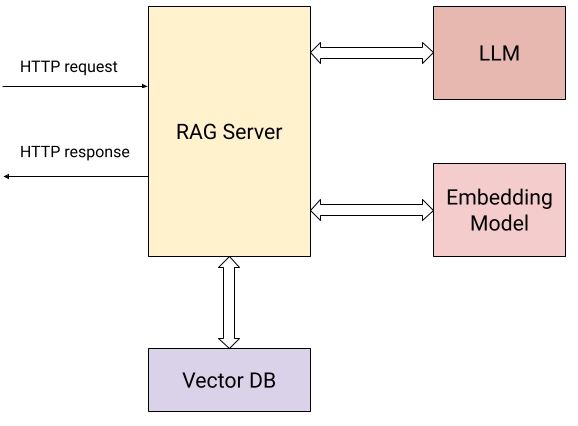
除了使用者傳送 HTTP 請求(上述兩個操作)之外,伺服器還與以下元件互動:
- 嵌入模型,用於計算提交的文件和使用者問題的向量嵌入。
- 向量資料庫,用於高效儲存和檢索嵌入。
- LLM,用於根據從知識庫收集的上下文提問。
具體來說,伺服器向用戶公開兩個 HTTP 端點:
/add/: POST {"documents": [{"text": "..."}, {"text": "..."}, ...]}:提交一系列文字文件給伺服器,以新增到其知識庫。對於此請求,伺服器將:
- 使用嵌入模型計算每個文件的向量嵌入。
- 將文件及其向量嵌入儲存在向量資料庫中。
/query/: POST {"content": "..."}:提交一個問題給伺服器。對於此請求,伺服器將:
- 使用嵌入模型計算問題的向量嵌入。
- 使用向量資料庫的相似性搜尋來查詢知識資料庫中最相關的文件。
- 使用簡單的提示工程,將第 (2) 步找到的最相關的文件作為上下文重新表述問題,然後將其傳送給 LLM,並將 LLM 的答案返回給使用者。
我們的演示使用的服務是:
- Google Gemini API,用於 LLM 和嵌入模型。
- Weaviate,一個本地託管的向量資料庫;Weaviate 是一個開源向量資料庫,用 Go 實現。
替換為其他等效服務應該非常簡單。事實上,這正是伺服器的第二種和第三種變體的目的!我們將從直接使用這些工具的第一種變體開始。
直接使用 Gemini API 和 Weaviate
Gemini API 和 Weaviate 都提供了方便的 Go SDK(客戶端庫),我們的第一個伺服器變體直接使用了它們。此變體的完整程式碼在此目錄中。
我們不會在本文件中複製全部程式碼,但請注意以下幾點:
結構:程式碼結構對於任何用 Go 編寫過 HTTP 伺服器的人來說都會很熟悉。Gemini 和 Weaviate 的客戶端庫會得到初始化,並將客戶端儲存在一個傳遞給 HTTP 處理程式的 state 值中。
路由註冊:使用 Go 1.22 中引入的路由增強功能,可以輕鬆設定伺服器的 HTTP 路由。
mux := http.NewServeMux()
mux.HandleFunc("POST /add/", server.addDocumentsHandler)
mux.HandleFunc("POST /query/", server.queryHandler)
併發:我們的伺服器的 HTTP 處理程式透過網路與其他服務進行通訊並等待響應。這對於 Go 來說不是問題,因為每個 HTTP 處理程式都在自己的 goroutine 中併發執行。這個 RAG 伺服器可以處理大量併發請求,每個處理程式的程式碼都是線性和同步的。
批次 API:由於 /add/ 請求可能提供大量要新增到知識庫的文件,因此伺服器利用了嵌入(embModel.BatchEmbedContents)和 Weaviate DB(rs.wvClient.Batch)的批次 API 以提高效率。
使用 LangChain for Go
我們的第二個 RAG 伺服器變體使用 LangChainGo 來完成相同的任務。
LangChain 是一個流行的 Python 框架,用於構建 LLM 驅動的應用程式。LangChainGo 是其 Go 版本。該框架提供了一些工具來構建由模組化元件組成的應用程式,並支援多種 LLM 提供商和向量資料庫,具有通用 API。這使得開發人員可以編寫與任何提供商相容的程式碼,並輕鬆切換提供商。
此變體的完整程式碼在此目錄中。閱讀程式碼時,您會注意到兩點:
首先,它比前一個變體要短一些。LangChainGo 負責將向量資料庫的完整 API 包裝成通用介面,因此初始化和處理 Weaviate 所需的程式碼更少。
其次,LangChainGo API 使切換提供商變得相當容易。假設我們想用另一個向量資料庫替換 Weaviate;在之前的變體中,我們必須重寫所有與向量資料庫互動的程式碼以使用新 API。有了 LangChainGo 這樣的框架,我們就不再需要這樣做了。只要 LangChainGo 支援我們感興趣的新向量資料庫,我們應該只需要更改伺服器中幾行程式碼,因為所有資料庫都實現了通用介面。
type VectorStore interface {
AddDocuments(ctx context.Context, docs []schema.Document, options ...Option) ([]string, error)
SimilaritySearch(ctx context.Context, query string, numDocuments int, options ...Option) ([]schema.Document, error)
}
使用 Genkit for Go
今年早些時候,Google 推出了Genkit for Go - 一個用於構建 LLM 驅動應用程式的新開源框架。Genkit 和 LangChain 有一些共同之處,但在其他方面有所不同。
與 LangChain 一樣,它提供了可以由不同提供商(作為外掛)實現的通用介面,因此更容易從一個提供商切換到另一個。然而,它並不試圖規定不同的 LLM 元件如何互動;相反,它專注於生產特性,如提示管理和工程,以及帶有整合開發工具的部署。
我們的第三個 RAG 伺服器變體使用 Genkit for Go 來完成相同的任務。其完整程式碼在此目錄中。
此變體與 LangChainGo 變體非常相似——它使用 LLM、嵌入器和向量資料庫的通用介面,而不是直接的提供商 API,這使得切換更加容易。此外,使用 Genkit 將 LLM 驅動的應用程式部署到生產環境要容易得多;我們在變體中沒有實現這一點,但如果您有興趣,可以隨時閱讀文件。
總結 - Go 用於 LLM 驅動的應用程式
本文中的示例只是展示了使用 Go 構建 LLM 驅動的應用程式的可能性。它演示瞭如何用相對較少的程式碼構建一個強大的 RAG 伺服器;最重要的是,這些示例由於 Go 的一些基本特性,具備了相當程度的生產就緒性。
處理 LLM 服務通常意味著向網路服務傳送 REST 或 RPC 請求,等待響應,然後根據該響應向其他服務傳送新請求,依此類推。Go 在所有這些方面都表現出色,提供了強大的工具來管理併發和協調網路服務的複雜性。
此外,Go 作為雲原生語言的出色效能和可靠性使其成為實現 LLM 生態系統更基礎構建塊的自然選擇。例如,請參閱 Ollama、LocalAI、Weaviate 或 Milvus 等專案。
下一篇文章:別名(Alias)的含義?
上一篇文章:分享您對 Go 開發的反饋
部落格索引