Go 部落格
gopls 擴充套件以應對不斷增長的 Go 生態系統
今年夏初,Go 團隊釋出了 v0.12 版本的 gopls,這是 Go 的 語言伺服器,其核心重寫使其能夠擴充套件到更大的程式碼庫。這是我們一年努力的成果,我們很高興能分享我們的進展,並略談新的架構及其對 gopls 未來意味著什麼。
自 v0.12 釋出以來,我們對新設計進行了微調,重點是使互動式查詢(如自動補全或查詢引用)的速度與 v0.11 一樣快,儘管記憶體中儲存的狀態要少得多。如果您還沒有嘗試過,我們希望您會試用一下。
$ go install golang.org/x/tools/gopls@latest
我們非常希望透過這次 簡短調查 瞭解您的使用體驗。
記憶體使用量和啟動時間降低
在深入細節之前,讓我們先看看結果!下圖顯示了 GitHub 上 28 個最受歡迎的 Go 儲存庫的啟動時間和記憶體使用量的變化。這些測量是在開啟隨機選擇的 Go 檔案並等待 gopls 完全載入其狀態後進行的,並且由於我們假設初始索引會在多次編輯會話中分攤,因此我們是在第二次開啟檔案時進行這些測量的。

在這些儲存庫中,平均節省量約為 75%,但記憶體減少是非線性的:隨著專案變大,記憶體使用的相對降低幅度也隨之增加。我們將在下面詳細解釋這一點。
Gopls 與不斷發展的 Go 生態系統
Gopls 為與語言無關的編輯器提供了類似 IDE 的功能,例如自動補全、格式化、交叉引用和重構。自 2018 年誕生以來,gopls 整合了許多分散的命令列工具,如 guru、gorename 和 goimports,並已成為 VS Code Go 擴充套件以及許多其他編輯器和 LSP 外掛的預設後端。也許您一直在透過編輯器使用 gopls 而未曾知曉——這就是我們的目標!
五年前,gopls 透過維護有狀態會話即可提高效能。而舊的命令列工具每次執行都必須從頭開始,gopls 可以儲存中間結果以顯著降低延遲。但所有這些狀態都有代價,隨著時間的推移,我們越來越多地 從使用者那裡聽到 gopls 高記憶體使用量幾乎令人無法忍受。
與此同時,Go 生態系統不斷發展,大型儲存庫中的程式碼量也在增加。 Go 工作區允許開發人員同時處理多個模組,而 容器化開發將語言伺服器置於資源日益受限的環境中。程式碼庫越來越大,開發環境越來越小。我們需要改變 gopls 擴充套件的方式以跟上步伐。
重新審視 gopls 的編譯器起源
在許多方面,gopls 類似於編譯器:它需要讀取、解析、型別檢查和分析 Go 原始檔,為此它使用了 Go 標準庫和 golang.org/x/tools 模組提供的許多編譯器 構建塊。這些構建塊使用了“符號程式設計”技術:在執行的編譯器中,有一個單一的物件或“符號”代表每個函式,例如 fmt.Println。任何對函式的引用都表示為指向其符號的指標。要測試兩個引用是否指代同一符號,您無需考慮名稱。只需比較指標。指標比字串小得多,指標比較也非常便宜,因此符號是表示程式等複雜結構的有效方式。
為了快速響應請求,gopls v0.11 將所有這些符號儲存在記憶體中,就好像 gopls 在“一次編譯您的整個程式”一樣。結果是記憶體佔用與正在編輯的原始碼成比例且大得多(例如,型別化的語法樹通常比原始碼文字大 30 倍!)。
獨立編譯
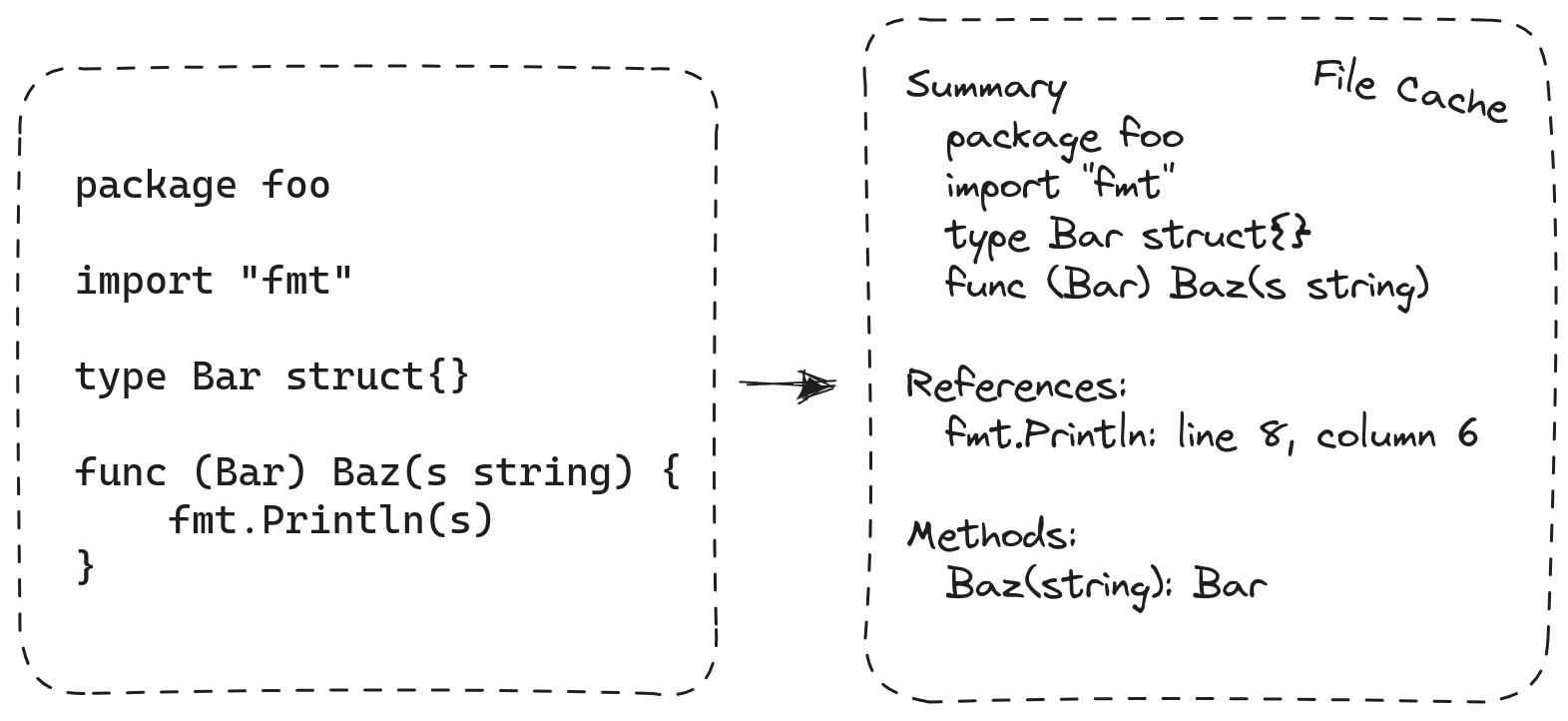
20 世紀 50 年代第一批編譯器的設計者很快發現了單片編譯的侷限性。他們的解決方案是將程式分解成單元並分別編譯每個單元。獨立編譯使得構建不適合記憶體的程式成為可能,透過分小塊構建。在 Go 中,單元是包。不同包的編譯不能完全分開:在編譯包 P 時,編譯器仍然需要關於 P 匯入的包提供的資訊。為了安排這一點,Go 構建系統會在 P 之前編譯 P 的所有匯入的包,Go 編譯器會為每個包匯出的 API 寫入一個緊湊的摘要。P 的匯入包的摘要作為 P 本身編譯的輸入。
Gopls v0.12 將獨立編譯引入 gopls,重用了編譯器使用的相同包摘要格式。這個想法很簡單,但細節之處存在微妙之處。我們重寫了以前檢查表示整個程式的_資料結構_的每個演算法,使其現在一次處理一個包,並將每個包的結果儲存到檔案中,就像編譯器發出目的碼一樣。例如,查詢函式的所有引用過去很簡單,只需在程式資料結構中搜索特定指標值的所有出現。現在,當 gopls 處理每個包時,它必須構造並儲存一個索引,將原始碼中的每個識別符號位置與它引用的符號名稱關聯起來。在查詢時,gopls 載入並搜尋這些索引。其他全域性查詢,例如“查詢實現”,也使用類似的技術。
與 go build 命令一樣,gopls 現在使用 基於檔案的快取 來儲存從每個包計算出的資訊摘要,包括每個宣告的型別、交叉引用索引以及每個型別的_方法集_。由於快取會在程序之間持久化,因此您會注意到第二次在工作區中啟動 gopls 時,它會更快地準備好提供服務,如果您執行兩個 gopls 例項,它們將協同工作。
此更改的結果是 gopls 的記憶體使用量與開啟的包數量及其直接匯入成正比。這就是我們在上圖中觀察到亞線性擴充套件的原因:隨著儲存庫變大,任何一個開啟的包所觀察到的專案_比例_變小。
細粒度失效
當您在一個包中進行更改時,只需要重新編譯直接或間接匯入該包的包。這個想法是自 20 世紀 70 年代的 Make 以來所有增量構建系統的基礎,gopls 自建立以來一直在使用它。實際上,LSP 啟用編輯器中的每一次按鍵都會啟動一個增量構建!然而,在一個大型專案中,間接依賴項會累加,導致這些增量重建速度過慢。事實證明,很多這項工作並非嚴格必需,因為大多數更改,例如在現有函式中新增語句,都不會影響匯入摘要。
如果您在一個檔案中進行小的更改,我們必須重新編譯該包,但如果更改不影響匯入摘要,我們就不必編譯任何其他包。更改的效果被“修剪”了。影響匯入摘要的更改需要重新編譯直接匯入該包的包,但大多數此類更改不會影響_那些_包的匯入摘要,在這種情況下,效果仍然被修剪,並避免重新編譯間接匯入者。由於這種修剪,低階包中的更改很少需要重新編譯_所有_間接依賴於該包的包。修剪的增量重建使工作量與每次更改的範圍成正比。這不是一個新想法:它由 Vesta 引入,並且也用於 go build。
v0.12 版本將類似的修剪技術引入 gopls,更進一步,透過基於語法分析實現更快的修剪啟發式。透過在記憶體中維護一個簡化的符號引用圖,gopls 可以快速確定包 c 中的更改是否可能透過引用鏈影響包 a。

在上例中,從 a 到 c 沒有引用鏈,因此即使 a 間接依賴於 c,它也不會受到 c 中更改的影響。
新的可能性
雖然我們對取得的效能改進感到滿意,但我們也對 gopls 的幾項新功能感到興奮,這些功能現在由於 gopls 不再受記憶體限制而變得可行。
首先是強大的靜態分析。以前,我們的靜態分析驅動程式必須操作 gopls 記憶體中的包表示,因此它無法分析依賴項:這樣做會引入太多額外的程式碼。隨著這一要求的解除,我們能夠在 gopls v0.12 中包含一個新的分析驅動程式,該驅動程式分析所有依賴項,從而提高精度。例如,gopls 現在會報告 Printf 格式錯誤的診斷,即使是在您圍繞 fmt.Printf 定義的自定義包裝器中。值得注意的是,go vet 多年來一直提供這種級別的精度,但 gopls 在每次編輯後無法即時做到這一點。現在它能做到了。
第二個是 更簡單的工作區配置和 對構建標籤的改進處理。這兩項功能都意味著 gopls 在您開啟機器上的任何 Go 檔案時都能“正常工作”,但如果沒有最佳化工作,這兩項功能都不可行(例如,每個構建配置都會成倍增加記憶體佔用!)。
試用一下!
除了可擴充套件性和效能改進之外,我們還修復了 許多 已報告的 bug 以及許多未報告的 bug,這些 bug 是我們在轉換過程中提高測試覆蓋率時發現的。
安裝最新的 gopls
$ go install golang.org/x/tools/gopls@latest
下一篇文章:Go 中的 WASI 支援
上一篇文章:Go 1.21 中的 Profile-guided 最佳化
部落格索引