Go 部落格
實驗、簡化、釋出
引言
這是我上週在 GopherCon 2019 上演講的部落格文章版本。
我們都在通往 Go 2 的道路上,但我們中的任何人都不知道這條路到底通向何方,有時甚至不知道路的方向。本文將討論我們是如何找到並遵循通往 Go 2 的道路的。這個過程是這樣的。
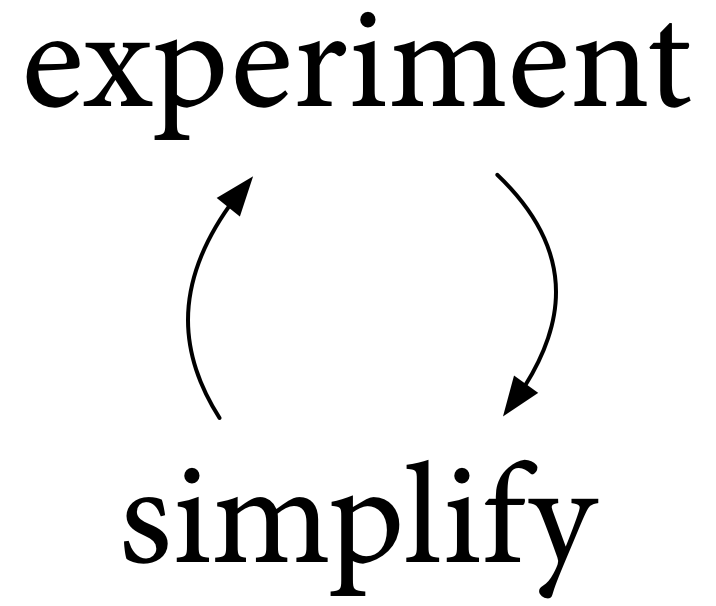
我們對現有的 Go 進行實驗,以更好地理解它,學習什麼有效,什麼無效。然後我們對可能的更改進行實驗,以更好地理解它們,再次學習什麼有效,什麼無效。根據我們在這些實驗中學到的東西,我們進行簡化。然後我們再次實驗。然後我們再次簡化。如此往復。如此往復。
簡化的四大“R”
在這個過程中,我們可以透過四種主要方式來簡化編寫 Go 程式時的整體體驗:重塑(reshaping)、重新定義(redefining)、移除(removing)和限制(restricting)。
透過重塑來簡化
我們簡化的第一種方式是將現有事物重塑成新的形式,從而使整體更簡單。
我們編寫的每一個 Go 程式都服務於測試 Go 本身的實驗。在 Go 的早期,我們很快就發現,編寫像 addToList 這樣的函式很常見。
func addToList(list []int, x int) []int {
n := len(list)
if n+1 > cap(list) {
big := make([]int, n, (n+5)*2)
copy(big, list)
list = big
}
list = list[:n+1]
list[n] = x
return list
}
我們會為位元組切片、字串切片等編寫相同的程式碼。我們的程式過於複雜,因為 Go 太簡單了。
因此,我們將程式中許多像 addToList 這樣的函式重塑為 Go 本身提供的一個函式。新增 append 使 Go 語言稍微複雜了一些,但總體而言,它使編寫 Go 程式的整體體驗更加簡單,即使算上學習 append 的成本。
這裡是另一個例子。對於 Go 1,我們查看了 Go 分發版中大量的開發工具,並將它們重塑為一個新命令。
5a 8g
5g 8l
5l cgo
6a gobuild
6cov gofix → go
6g goinstall
6l gomake
6nm gopack
8a govet
go 命令現在如此重要,以至於很容易忘記我們曾經在沒有它並且付出了多少額外工作的情況下走過了多遠。
我們為 Go 分發版添加了程式碼和複雜性,但總體而言,我們簡化了編寫 Go 程式的體驗。新的結構也為其他有趣的實驗創造了空間,我們稍後會看到。
透過重新定義來簡化
我們簡化的第二種方式是透過重新定義已有的功能,使其能夠做更多的事情。就像透過重塑來簡化一樣,透過重新定義來簡化也使程式編寫起來更簡單,但現在無需學習新東西。
例如,append 最初被定義為只能從切片讀取。將一個位元組切片附加到另一個位元組切片時,您可以附加另一個位元組切片中的位元組,但不能附加字串中的位元組。我們重新定義了 append,允許從字串附加,而無需向語言新增任何新內容。
var b []byte
var more []byte
b = append(b, more...) // ok
var b []byte
var more string
b = append(b, more...) // ok later
透過移除來簡化
我們簡化的第三種方式是移除功能,當它不像我們預期的那樣有用或不那麼重要時。移除功能意味著少學一樣東西,少修復一個 bug,少一些分心或被錯誤使用的東西。當然,移除也會迫使使用者更新現有程式,可能使它們變得更復雜,以彌補移除。但總體結果仍然是編寫 Go 程式的流程可以變得更簡單。
一個例子是當我們從語言中移除了非阻塞通道操作的布林形式時。
ok := c <- x // before Go 1, was non-blocking send
x, ok := <-c // before Go 1, was non-blocking receive
使用 select 也可以實現這些操作,這使得選擇使用哪種形式變得令人困惑。移除它們在不降低語言功能的前提下簡化了語言。
透過限制來簡化
我們也可以透過限制允許的範圍來簡化。從第一天起,Go 就限制了 Go 原始檔的編碼:它們必須是 UTF-8。這一限制使嘗試讀取 Go 原始檔的每個程式都更簡單。這些程式不必擔心以 Latin-1、UTF-16、UTF-7 或其他任何編碼方式編碼的 Go 原始檔。
另一個重要的限制是 gofmt 用於程式格式化。任何不使用 gofmt 格式化的 Go 程式碼都會被拒絕,但我們已經建立了一個約定,即重寫 Go 程式的工具應將其保留為 gofmt 格式。如果您也將程式保留為 gofmt 格式,那麼這些重寫工具將不會進行任何格式化更改。當您比較前後差異時,您看到的唯一差異就是實際更改。這一限制簡化了程式重寫工具,並促成了 goimports、gorename 等許多成功的實驗。
Go 開發流程
這種實驗和簡化的迴圈是我們過去十年所做的事情的一個好模型,但它有一個問題:它太簡單了。我們不能只進行實驗和簡化。
我們必須釋出結果。我們必須使其可用。當然,使用它會帶來更多的實驗,以及更多的簡化,過程會不斷迴圈。
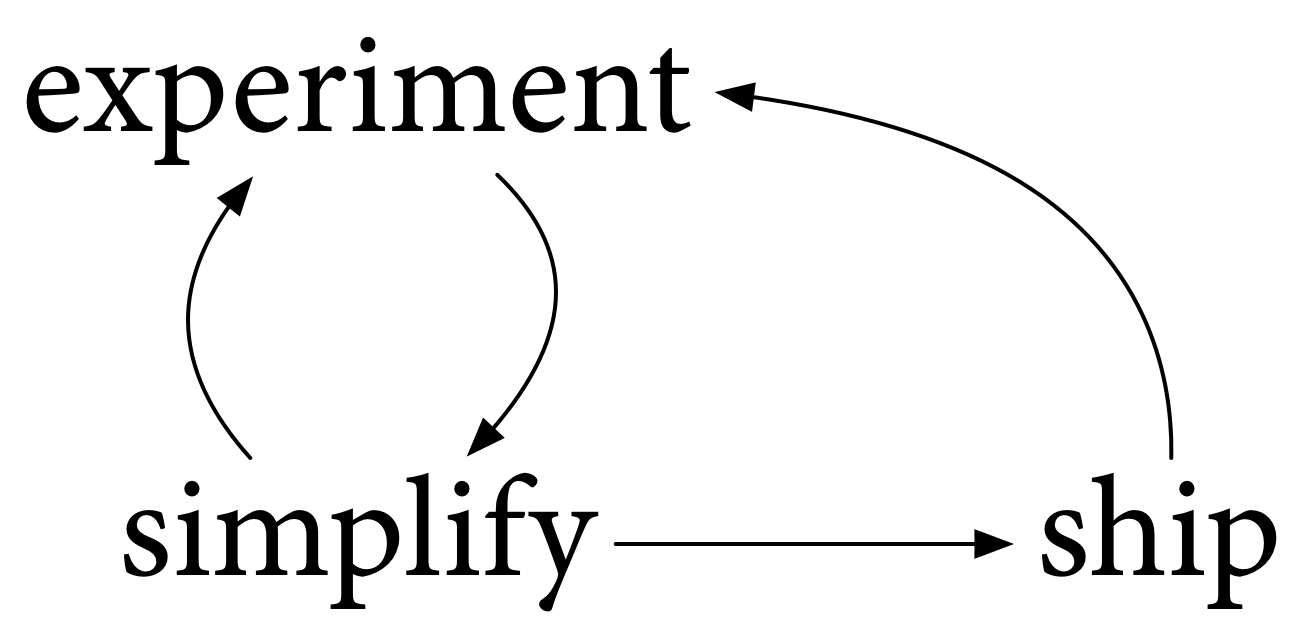
我們第一次向大家釋出 Go 是在 2009 年 11 月 10 日。然後,在你們的幫助下,我們在 2012 年 3 月一起釋出了 Go 1。從那時起,我們已經發布了十二個 Go 版本。所有這些都是重要的里程碑,旨在實現更多實驗,幫助我們更多地瞭解 Go,當然,也使 Go 可用於生產環境。
當我們釋出 Go 1 時,我們明確地將重點轉移到使用 Go 上,以便在嘗試任何涉及語言更改的進一步簡化之前,更好地理解這個版本的語言。我們需要花時間進行實驗,真正瞭解什麼有效,什麼無效。
當然,自 Go 1 以來我們已經發布了十二個版本,所以我們仍在進行實驗、簡化和釋出。但是,我們專注於如何簡化 Go 開發,而無需重大的語言更改,也無需破壞現有的 Go 程式。例如,Go 1.5 釋出了第一個併發垃圾收集器,隨後的版本對其進行了改進,透過消除暫停時間作為持續的擔憂來簡化 Go 開發。
在 2017 年的 Gophercon 上,我們宣佈經過五年的實驗,是時候重新考慮對簡化 Go 開發進行重大更改了。我們通往 Go 2 的道路與通往 Go 1 的道路相同:實驗、簡化和釋出,朝著簡化 Go 開發的總體目標前進。
對於 Go 2,我們認為最重要要解決的具體主題是錯誤處理、泛型和依賴項。此後,我們意識到另一個重要主題是開發工具。
本文的其餘部分將討論我們在這些領域的工作如何遵循這條道路。沿途,我們將繞道而行,停下來詳細檢查即將隨 Go 1.13 一起釋出的錯誤處理的詳細技術內容。
Errors
當所有輸入都有效且正確,並且程式所依賴的一切都沒有失敗時,編寫一個在所有情況下都能正確執行的程式就已經足夠困難了。當引入錯誤時,編寫一個無論發生什麼錯誤都能正確執行的程式會更加困難。
作為思考 Go 2 的一部分,我們想更好地瞭解 Go 是否能幫助簡化這項工作。
有兩個方面可能被簡化:錯誤值和錯誤語法。我們將逐一討論,並以我承諾的 Go 1.13 錯誤值更改的技術細節為重點。
錯誤值
錯誤值必須從某個地方開始。這是 os 包第一個版本中的 Read 函式。
export func Read(fd int64, b *[]byte) (ret int64, errno int64) {
r, e := syscall.read(fd, &b[0], int64(len(b)));
return r, e
}
那時還沒有 File 型別,也沒有錯誤型別。Read 和該包中的其他函式直接返回底層 Unix 系統呼叫的 errno int64。
這段程式碼是在 2008 年 9 月 10 日下午 12:14 提交的。和當時所有程式碼一樣,這是一個實驗,程式碼更改很快。兩個小時零五分鐘後,API 發生了變化。
export type Error struct { s string }
func (e *Error) Print() { … } // to standard error!
func (e *Error) String() string { … }
export func Read(fd int64, b *[]byte) (ret int64, err *Error) {
r, e := syscall.read(fd, &b[0], int64(len(b)));
return r, ErrnoToError(e)
}
這個新 API 引入了第一個 Error 型別。一個錯誤包含一個字串,並可以返回該字串並將其列印到標準錯誤。
這裡的意圖是推廣到整數程式碼之外。我們從過去的經驗知道,作業系統錯誤號的表示方法太有限了,不將關於錯誤的全部細節塞進 64 位整數將使程式更簡單。使用錯誤字串在過去對我們來說效果不錯,所以我們在這裡也做了同樣的事情。這個新 API 持續了七個月。
第二年四月,在更多使用介面的經驗之後,我們決定進一步推廣,並透過將 os.Error 型別本身變成一個介面,允許使用者定義的錯誤實現。我們透過移除 Print 方法來簡化。
兩年後的 Go 1,根據 Roger Peppe 的建議,os.Error 成為了內建的 error 型別,並將 String 方法重新命名為 Error。從那時起就沒有改變過。但我們編寫了許多 Go 程式,因此我們在如何最好地實現和使用錯誤方面進行了大量實驗。
錯誤即值
將 error 作為一個簡單的介面,並允許許多不同的實現,意味著我們擁有整個 Go 語言來定義和檢查錯誤。我們喜歡說 錯誤就是值,與其他任何 Go 值一樣。
這裡有一個例子。在 Unix 上,嘗試撥打網路連線最終會使用 connect 系統呼叫。該系統呼叫返回 syscall.Errno,這是一個命名整數型別,代表系統呼叫錯誤號並實現了 error 介面。
package syscall
type Errno int64
func (e Errno) Error() string { ... }
const ECONNREFUSED = Errno(61)
... err == ECONNREFUSED ...
syscall 包還為主機作業系統定義的錯誤號定義了命名常量。在這種情況下,在此係統上,ECONNREFUSED 是數字 61。從函式獲取錯誤的 कोड 可以透過普通的 值相等性 來測試錯誤是否為 ECONNREFUSED。
往上一層,在 os 包中,任何系統呼叫失敗都使用一個更大的錯誤結構來報告,該結構記錄了嘗試的操作以及錯誤。這些結構很少。這個,SyscallError,描述了一個呼叫特定系統呼叫但沒有記錄附加資訊的錯誤。
package os
type SyscallError struct {
Syscall string
Err error
}
func (e *SyscallError) Error() string {
return e.Syscall + ": " + e.Err.Error()
}
再往上一層,在 net 包中,任何網路故障都使用一個更大的錯誤結構來報告,該結構記錄了周圍網路操作的詳細資訊,例如撥號或監聽,以及涉及的網路和地址。
package net
type OpError struct {
Op string
Net string
Source Addr
Addr Addr
Err error
}
func (e *OpError) Error() string { ... }
將這些組合起來,net.Dial 等操作返回的錯誤可以格式化為字串,但它們也是結構化的 Go 資料值。在這種情況下,錯誤是 net.OpError,它為 os.SyscallError 添加了上下文,而 os.SyscallError 又為 syscall.Errno 添加了上下文。
c, err := net.Dial("tcp", "localhost:50001")
// "dial tcp [::1]:50001: connect: connection refused"
err is &net.OpError{
Op: "dial",
Net: "tcp",
Addr: &net.TCPAddr{IP: ParseIP("::1"), Port: 50001},
Err: &os.SyscallError{
Syscall: "connect",
Err: syscall.Errno(61), // == ECONNREFUSED
},
}
當我們說錯誤是值時,我們既指整個 Go 語言都可以用來定義它們,也指整個 Go 語言都可以用來檢查它們。
這裡有一個來自 net 包的例子。事實證明,當您嘗試連線套接字時,大多數時候您會連線成功或收到連線被拒絕的錯誤,但有時您可能會收到一個虛假的 EADDRNOTAVAIL,沒有好的原因。Go 透過重試來保護使用者程式免受這種失敗模式的影響。為此,它必須檢查錯誤結構以找出內部的 syscall.Errno 是否為 EADDRNOTAVAIL。
這是程式碼。
func spuriousENOTAVAIL(err error) bool {
if op, ok := err.(*OpError); ok {
err = op.Err
}
if sys, ok := err.(*os.SyscallError); ok {
err = sys.Err
}
return err == syscall.EADDRNOTAVAIL
}
一個 型別斷言 去除了任何 net.OpError 的包裝。然後第二個型別斷言去除了任何 os.SyscallError 的包裝。然後函式檢查解包後的錯誤是否等於 EADDRNOTAVAIL。
透過多年經驗,透過對 Go 錯誤的這些實驗,我們學到的是,能夠定義任意的 error 介面實現,同時擁有完整的 Go 語言來構造和解構錯誤,並且不需要使用任何單一的實現,這是非常強大的。
這些屬性——即錯誤是值,並且沒有一個強制的錯誤實現——都很重要,值得保留。
不強制要求單一的錯誤實現,使得每個人都可以實驗錯誤可能提供的附加功能,從而產生了許多包,例如 github.com/pkg/errors、gopkg.in/errgo.v2、github.com/hashicorp/errwrap、upspin.io/errors、github.com/spacemonkeygo/errors 等。
然而,不受限制的實驗有一個問題是,作為客戶端,您必須針對您可能遇到的所有可能實現的並集進行程式設計。對於 Go 2,一個看似值得探索的簡化是定義一個標準版本,包含常用新增的功能,以可選介面的形式,以便不同的實現能夠互操作。
Unwrap (解包)
在這些包中最常新增的功能是某種可以呼叫的方法,用於移除錯誤的上下文,返回內部的錯誤。包使用不同的名稱和含義來表示此操作,有時它移除一個級別的上下文,有時它移除儘可能多的級別。
對於 Go 1.13,我們引入了一個約定,即一個新增可移除上下文到內部錯誤的實現,應該實現一個 Unwrap 方法,該方法返回內部錯誤,解包上下文。如果沒有適合暴露給呼叫者的內部錯誤,要麼錯誤不應該有 Unwrap 方法,要麼 Unwrap 方法應該返回 nil。
// Go 1.13 optional method for error implementations.
interface {
// Unwrap removes one layer of context,
// returning the inner error if any, or else nil.
Unwrap() error
}
呼叫此可選方法的途徑是呼叫輔助函式 errors.Unwrap,該函式處理錯誤本身為 nil 或根本沒有 Unwrap 方法的情況。
package errors
// Unwrap returns the result of calling
// the Unwrap method on err,
// if err’s type defines an Unwrap method.
// Otherwise, Unwrap returns nil.
func Unwrap(err error) error
我們可以使用 Unwrap 方法來編寫一個更簡單、更通用的 spuriousENOTAVAIL 版本。而不是查詢特定的錯誤包裝實現,如 net.OpError 或 os.SyscallError,通用版本可以迴圈呼叫 Unwrap 來移除上下文,直到它達到 EADDRNOTAVAIL 或沒有錯誤為止。
func spuriousENOTAVAIL(err error) bool {
for err != nil {
if err == syscall.EADDRNOTAVAIL {
return true
}
err = errors.Unwrap(err)
}
return false
}
然而,這個迴圈非常普遍,以至於 Go 1.13 定義了第二個函式 errors.Is,它會重複解包錯誤以查詢特定目標。因此,我們可以用對 errors.Is 的單個呼叫來替換整個迴圈。
func spuriousENOTAVAIL(err error) bool {
return errors.Is(err, syscall.EADDRNOTAVAIL)
}
在這一點上,我們可能甚至不需要定義這個函式;直接在呼叫點呼叫 errors.Is 會同樣清晰,並且更簡單。
Go 1.13 還引入了一個函式 errors.As,它會解包直到找到特定的實現型別。
如果您想編寫可以處理任意包裝錯誤的 बढ़त,errors.Is 是錯誤相等性檢查的包裝感知版本。
err == target
→
errors.Is(err, target)
而 errors.As 是錯誤型別斷言的包裝感知版本。
target, ok := err.(*Type)
if ok {
...
}
→
var target *Type
if errors.As(err, &target) {
...
}
是否解包?
是否使錯誤能夠被解包是一個 API 決策,就像是否匯出結構欄位是一個 API 決策一樣。有時適合將該詳細資訊暴露給呼叫程式碼,有時則不適合。當適合時,實現 Unwrap。當不適合時,不要實現 Unwrap。
到目前為止,fmt.Errorf 一直沒有將格式化為 %v 的底層錯誤暴露給呼叫方檢查。也就是說,fmt.Errorf 的結果無法被解包。考慮這個例子。
// errors.Unwrap(err2) == nil
// err1 is not available (same as earlier Go versions)
err2 := fmt.Errorf("connect: %v", err1)
如果 err2 返回給呼叫方,那麼呼叫方將永遠無法開啟 err2 並訪問 err1。我們在 Go 1.13 中保留了這一特性。
對於您確實希望允許解包 fmt.Errorf 結果的情況,我們還添加了一個新的列印動詞 %w,它像 %v 一樣格式化,需要一個錯誤值引數,並使結果錯誤的 Unwrap 方法返回該引數。在我們的例子中,假設我們將 %v 替換為 %w。
// errors.Unwrap(err4) == err3
// (%w is new in Go 1.13)
err4 := fmt.Errorf("connect: %w", err3)
現在,如果 err4 返回給呼叫方,呼叫方可以使用 Unwrap 來檢索 err3。
重要的是要注意,像“總是使用 %v(或從不實現 Unwrap)”或“總是使用 %w(或總是實現 Unwrap)”這樣的絕對規則與“從不匯出結構欄位”或“總是匯出結構欄位”這樣的絕對規則一樣錯誤。相反,正確的決定取決於呼叫者是否應該能夠檢查和依賴使用 %w 或實現 Unwrap 所暴露的附加資訊。
作為對這一點的一個說明,標準庫中所有已經有一個匯出 Err 欄位的錯誤包裝型別現在也有一個返回該欄位的 Unwrap 方法,但具有未匯出錯誤欄位的實現則沒有,並且對 fmt.Errorf 使用 %v 的現有用法仍然使用 %v,而不是 %w。
錯誤值列印(已放棄)
與 Unwrap 的設計草案一起,我們還發布了一個 用於更豐富的錯誤列印的可選方法的設計草案,包括堆疊幀資訊和對本地化、翻譯錯誤的支援。
// Optional method for error implementations
type Formatter interface {
Format(p Printer) (next error)
}
// Interface passed to Format
type Printer interface {
Print(args ...interface{})
Printf(format string, args ...interface{})
Detail() bool
}
這個比 Unwrap 簡單,我在這裡不詳述。在我們與 Go 社群在冬季討論設計時,我們瞭解到該設計不夠簡單。它對單個錯誤型別的實現來說太難了,而且對現有程式的幫助不夠。總的來說,它並沒有簡化 Go 開發。
因此,在這次社群討論之後,我們放棄了這個列印設計。
錯誤語法
以上是錯誤值。讓我們簡要看看錯誤語法,這是另一個被放棄的實驗。
這是標準庫中 compress/lzw/writer.go 的一些程式碼。
// Write the savedCode if valid.
if e.savedCode != invalidCode {
if err := e.write(e, e.savedCode); err != nil {
return err
}
if err := e.incHi(); err != nil && err != errOutOfCodes {
return err
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
if err := e.write(e, eof); err != nil {
return err
}
一眼看去,這段程式碼大約有一半是錯誤檢查。我讀它時眼睛都會發花。我們知道,寫起來冗長、讀起來冗長的程式碼很容易被誤讀,這使得它很容易成為隱藏 bug 的溫床。例如,這三個錯誤檢查中的一個與其他不同,這是一個很容易在快速瀏覽時忽略的事實。如果您在除錯這段程式碼,需要多長時間才能注意到這一點?
在去年的 Gophercon 上,我們 提出了一個新控制流結構的草案設計,該結構由關鍵字 check 標記。Check 消耗函式呼叫或表示式的錯誤結果。如果錯誤非 nil,check 會返回該錯誤。否則,check 的計算結果為呼叫中的其他結果。我們可以使用 check 來簡化 lzw 程式碼。
// Write the savedCode if valid.
if e.savedCode != invalidCode {
check e.write(e, e.savedCode)
if err := e.incHi(); err != errOutOfCodes {
check err
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
check e.write(e, eof)
同一程式碼的這個版本使用了 check,它刪除了四行程式碼,更重要的是突出了 e.incHi 的呼叫允許返回 errOutOfCodes。
也許最重要的是,該設計還允許定義錯誤處理塊,以便在後續檢查失敗時執行。這將允許您只編寫一次共享的上下文新增程式碼,就像在這個片段中一樣。
handle err {
err = fmt.Errorf("closing writer: %w", err)
}
// Write the savedCode if valid.
if e.savedCode != invalidCode {
check e.write(e, e.savedCode)
if err := e.incHi(); err != errOutOfCodes {
check err
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
check e.write(e, eof)
本質上,check 是編寫 if 語句的簡寫方式,而 handle 類似於 defer,但僅用於錯誤返回路徑。與 C++ 中的異常不同,此設計保留了 Go 的一個重要特性,即每個潛在的失敗呼叫都在程式碼中顯式標記,現在使用 check 關鍵字而不是 if err != nil。
此設計的主要問題是 handle 與 defer 的重疊太多,並且以令人困惑的方式重疊。
在五月份,我們釋出了 一個包含三個簡化功能的新設計:為了避免與 defer 的混淆,該設計放棄了 handle,而是使用 defer;為了匹配 Rust 和 Swift 中的類似想法,該設計將 check 重新命名為 try;為了允許以現有解析器(如 gofmt)能夠識別的方式進行實驗,它將 check(現在是 try)從關鍵字更改為內建函式。
現在相同的程式碼看起來會像這樣。
defer errd.Wrapf(&err, "closing writer")
// Write the savedCode if valid.
if e.savedCode != invalidCode {
try(e.write(e, e.savedCode))
if err := e.incHi(); err != errOutOfCodes {
try(err)
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
try(e.write(e, eof))
我們花費了整個六月在 GitHub 上公開討論這個提議。
check 或 try 的基本思想是縮短每個錯誤檢查處重複的語法量,特別是從檢視中移除 return 語句,保持錯誤檢查的顯式性,並更好地突出有趣的變體。然而,在公開反饋討論中提出的一個有趣觀點是,沒有顯式的 if 語句和 return,就沒有地方放置除錯列印,沒有地方放置斷點,也沒有程式碼可以在程式碼覆蓋率結果中顯示為未執行。我們追求的好處是以使這些情況更加複雜為代價的。總體而言,基於這一點以及其他考慮因素,不確定整體結果是否會簡化 Go 開發,因此我們放棄了這個實驗。
以上就是關於錯誤處理的全部內容,這是今年的一項主要重點。
泛型
現在來看看一些不太有爭議的內容:泛型。
我們為 Go 2 確定的第二個重大主題是某種編寫型別引數程式碼的方法。這將能夠編寫泛型資料結構,以及編寫與任何型別的切片、任何型別的通道或任何型別的對映一起工作的泛型函式。例如,這是一個泛型通道過濾器。
// Filter copies values from c to the returned channel,
// passing along only those values satisfying f.
func Filter(type value)(f func(value) bool, c <-chan value) <-chan value {
out := make(chan value)
go func() {
for v := range c {
if f(v) {
out <- v
}
}
close(out)
}()
return out
}
我們從 Go 開始工作起就一直在考慮泛型,並且在 2010 年寫了並否決了我們的第一個具體設計。到 2013 年底,我們又寫了三個設計並被否決。四個被放棄的實驗,但不是失敗的實驗。我們從它們中學到了東西,就像我們從 check 和 try 中學到的一樣。每一次,我們都學到通往 Go 2 的道路不在那個確切的方向,並注意到其他可能值得探索的方向。但到 2013 年,我們決定需要專注於其他問題,所以我們將整個主題擱置了幾年。
去年,我們開始重新探索和實驗,並在去年的 Gophercon 上提出了一個基於契約思想的 新設計。我們繼續進行實驗和簡化,並與程式語言理論專家合作,以更好地理解該設計。
總的來說,我希望我們正朝著一個好的方向前進,朝著一個將簡化 Go 開發的設計。即便如此,我們也可能發現這個設計不起作用。我們可能不得不放棄這個實驗,並根據我們學到的東西調整我們的道路。我們將拭目以待。
在 Gophercon 2019 上,Ian Lance Taylor 談論了為什麼我們可能想為 Go 新增泛型,並簡要預覽了最新的設計草案。詳情請參閱他的部落格文章《為什麼需要泛型?》。
依賴項
我們為 Go 2 確定的第三個重大主題是依賴項管理。
2010 年,我們釋出了一個名為 goinstall 的工具,我們稱之為“包安裝的實驗”。它下載依賴項並將它們儲存在您的 Go 分發樹中的 GOROOT 裡。
在對 goinstall 進行實驗的過程中,我們瞭解到 Go 分發版和已安裝的包應該分開存放,這樣就可以在不丟失所有 Go 包的情況下更改到新的 Go 分發版。因此,在 2011 年,我們引入了 GOPATH,一個環境變數,用於指定在 Go 主要分發版中找不到的包的查詢位置。
新增 GOPATH 創造了更多存放 Go 包的地方,但總體上簡化了 Go 開發,因為它將 Go 分發版與 Go 庫分開了。
相容性
goinstall 實驗有意省略了明確的包版本概念。相反,goinstall 始終下載最新副本。我們這樣做是為了能夠專注於包安裝的其他設計問題。
Goinstall 在 Go 1 中成為了 go get。當人們詢問版本時,我們鼓勵他們透過建立額外的工具進行實驗,他們也這樣做了。我們鼓勵包作者為使用者提供與 Go 1 庫相同的向後相容性。引用 Go FAQ
“旨在公開使用的包應在演變過程中努力保持向後相容性。
如果需要不同的功能,請新增新名稱而不是更改舊名稱。
如果需要完全中斷,請建立一個具有新匯入路徑的新包。”
這個約定透過限制作者可以做什麼來簡化使用包的整體體驗:避免對 API 進行破壞性更改;為新功能提供新名稱;併為整個新包設計提供新匯入路徑。
當然,人們一直在實驗。最有趣的實驗之一是由 Gustavo Niemeyer 發起的。他建立了一個名為 gopkg.in 的 Git 重定向器,它為不同的 API 版本提供了不同的匯入路徑,以幫助包作者遵循為新包設計提供新匯入路徑的約定。
例如,GitHub 儲存庫 go-yaml/yaml 中的 Go 原始碼在 v1 和 v2 語義版本標籤中具有不同的 API。gopkg.in 伺服器提供了這些不同的匯入路徑 gopkg.in/yaml.v1 和 gopkg.in/yaml.v2。
提供向後相容性的約定,以便可以使用新版本的包來替代舊版本,這使得 go get 的非常簡單的規則——“始終下載最新副本”——即使在今天也能很好地工作。
版本控制和打包
但在生產環境中,您需要更精確地確定依賴項版本,以使構建可重現。
許多人實驗過它應該是什麼樣子,構建了滿足他們需求的工具,包括 Keith Rarick 的 goven(2012)和 godep(2013),Matt Butcher 的 glide(2014),以及 Dave Cheney 的 gb(2015)。所有這些工具都使用將依賴項包複製到您自己的原始碼控制儲存庫的模型。用於使這些包可匯入的確切機制各不相同,但它們都比看起來應該的要複雜。
在社群廣泛討論之後,我們採納了 Keith Rarick 的一項提議,即新增對引用複製的依賴項的顯式支援,而無需 GOPATH 技巧。這是透過重塑來簡化的:就像 addToList 和 append 一樣,這些工具已經在實現這個概念,但比它需要的更笨拙。新增對 vendor 目錄的顯式支援總體上簡化了這些用法。
在 go 命令中釋出 vendor 目錄導致了對 vendoring 本身的更多實驗,我們意識到我們引入了一些問題。最嚴重的是我們丟失了包的唯一性。以前,在任何給定的構建過程中,一個匯入路徑可能出現在許多不同的包中,並且所有匯入都指向同一個目標。現在隨著 vendoring,不同包中的相同匯入路徑可能指向該包的不同 vendor 副本,所有這些都將出現在最終生成的二進位制檔案中。
那時,我們還沒有為這個屬性命名:包的唯一性。這只是 GOPATH 模型的工作方式。直到它消失,我們才完全理解它。
這裡與 check 和 try 錯誤語法提案有一個相似之處。在這種情況下,我們依賴於可見的 return 語句的工作方式,直到我們考慮移除它之前,我們並沒有完全理解它。
當我們新增 vendor 目錄支援時,有許多不同的工具來管理依賴項。我們認為,關於 vendor 目錄的格式和 vendoring 元資料的清晰約定將允許各種工具互操作,就像關於如何在文字檔案中儲存 Go 程式一樣,這使得 Go 編譯器、文字編輯器和 goimports、gorename 等工具之間能夠互操作。
事實證明,這是天真的樂觀。vendoring 工具在語義上都有細微差別。互操作將需要更改所有這些工具以就語義達成一致,這可能會破壞它們各自的使用者。融合沒有發生。
Dep
在 2016 年的 Gophercon 上,我們開始著手定義一個單一的工具來管理依賴項。作為該工作的一部分,我們對不同型別的使用者進行了調查,以瞭解他們在依賴項管理方面的需求,然後一個團隊開始開發一個新工具,這個工具後來成為了 dep。
Dep 旨在取代所有現有的依賴項管理工具。目標是透過將現有的不同工具重塑為一個工具來簡化。它部分實現了這一點。Dep 還透過在專案樹的頂部只有一個 vendor 目錄,為其使用者恢復了包的唯一性。
但是 dep 也引入了一個我們花了很長時間才完全理解的嚴重問題。問題在於 dep 採納了 glide 的設計選擇,即支援並鼓勵對給定包進行不相容的更改而不改變匯入路徑。
這是一個例子。假設您正在構建自己的程式,並且需要一個配置檔案,因此您使用了流行的 Go YAML 包的第 2 版。

現在假設您的程式匯入了 Kubernetes 客戶端。事實證明,Kubernetes 大量使用 YAML,並且它使用了同一個流行包的第 1 版。
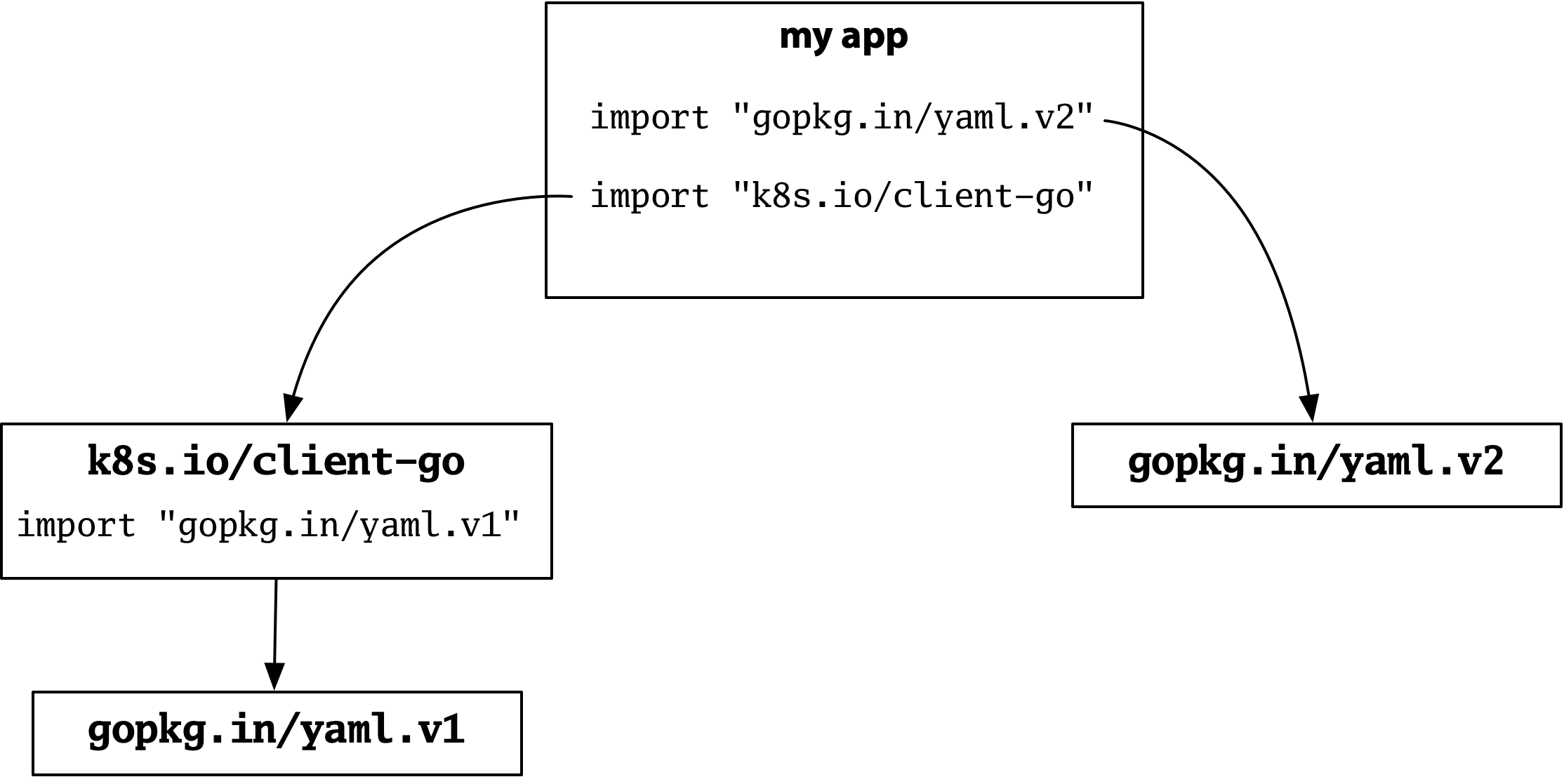
第 1 版和第 2 版具有不相容的 API,但它們也有不同的匯入路徑,因此對於給定匯入指的是哪個版本沒有歧義。Kubernetes 獲取第 1 版,您的配置解析器獲取第 2 版,一切正常。
Dep 放棄了這種模型。yaml 包的第 1 版和第 2 版現在將具有相同的匯入路徑,從而產生衝突。使用相同的匯入路徑來表示兩個不相容的版本,再加上包的唯一性,使得您無法構建以前可以構建的這個程式。
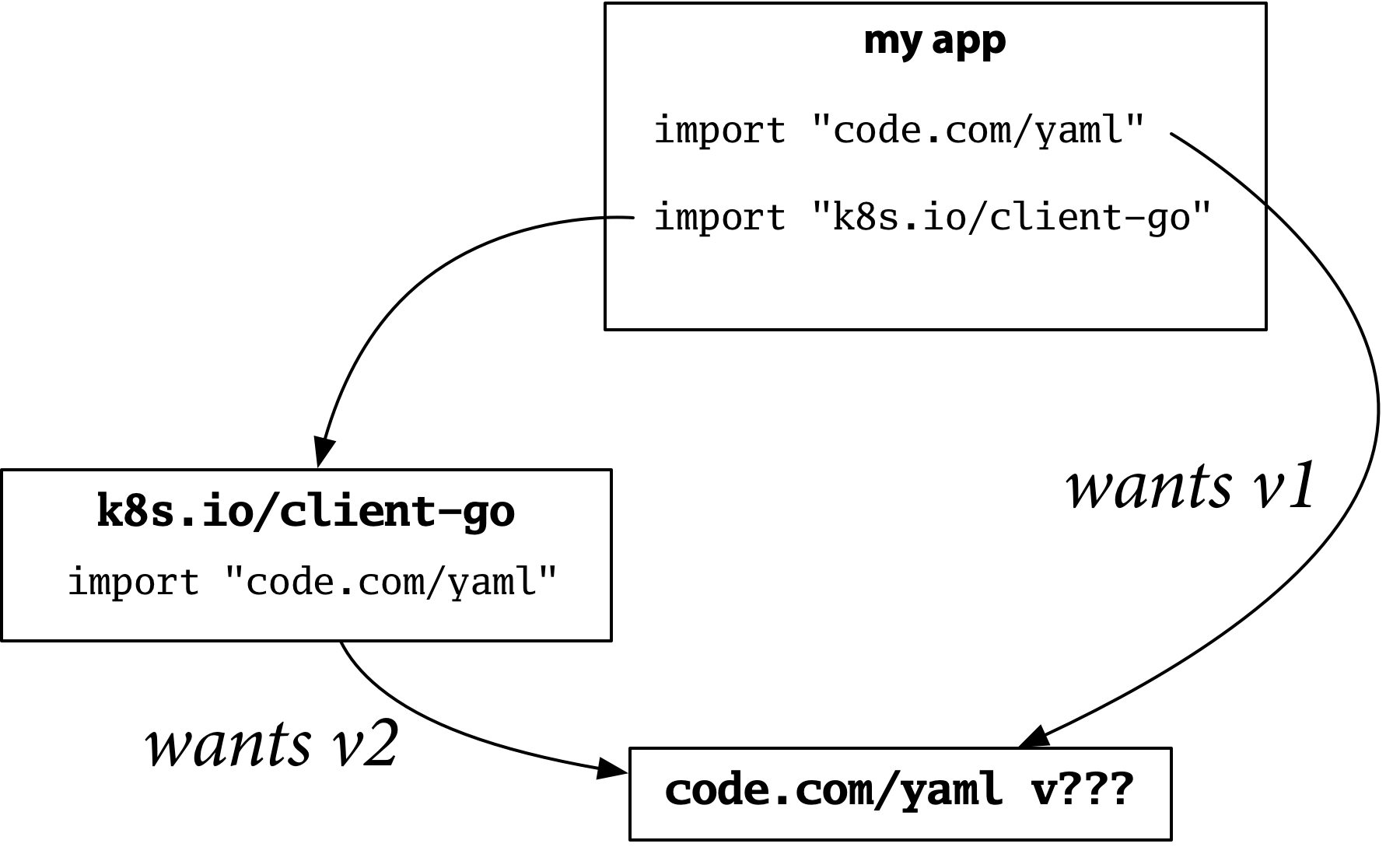
我們花了很長時間才理解這個問題,因為我們長期以來一直應用“新 API 意味著新匯入路徑”的約定,以至於我們把它當作理所當然。dep 實驗幫助我們更好地理解了這個約定,並給它起了一個名字:匯入相容性規則。
“如果一箇舊包和一個新包具有相同的匯入路徑,那麼新包必須向後相容舊包。”
Go Modules
我們借鑑了 dep 實驗中的優點以及我們學到的缺點,並進行了一個名為 vgo 的新設計實驗。在 vgo 中,包遵循匯入相容性規則,以便我們提供包的唯一性,但仍然不會破壞我們剛剛看到的那個構建。這使我們能夠簡化設計的其他部分。
除了恢復匯入相容性規則之外,vgo 設計的另一個重要部分是為一組包的概念命名,並允許將該分組與原始碼儲存庫邊界分離。一組 Go 包的名稱是模組,因此我們現在將該系統稱為 Go modules。
Go modules 現在已與 go 命令整合,完全無需複製 vendor 目錄。
替換 GOPATH
隨著 Go modules 的出現,GOPATH 作為全域性名稱空間的時代宣告結束。將現有 Go 用法和工具轉換為 modules 所需的大部分繁重工作都源於這一變化,即從 GOPATH 遷移。
GOPATH 的基本思想是,GOPATH 目錄樹是正在使用的版本全域性真相的來源,並且在使用版本時,您在不同目錄之間移動時版本不會改變。但全域性 GOPATH 模式與生產環境中對每個專案進行可重現構建的要求直接衝突,而後者在許多重要方面簡化了 Go 的開發和部署體驗。
每個專案可重現構建意味著,當您在專案 A 的檢出中工作時,您將獲得與其他專案 A 開發人員在該提交時獲得的依賴項版本相同的集合,由 go.mod 檔案定義。當您切換到專案 B 的檢出時,您將獲得該專案的選定依賴項版本,與專案 B 的其他開發人員獲得的相同。但這些可能與專案 A 不同。當您從專案 A 切換到專案 B 時,依賴項版本集合的變化對於保持您的開發與 A 和 B 上的其他開發人員同步是必要的。不能再存在一個全域性 GOPATH 了。
採用 modules 的複雜性大部分直接源於一個全域性 GOPATH 的丟失。包的原始碼在哪裡?以前,答案僅取決於您的 GOPATH 環境變數,而大多數人很少更改它。現在,答案取決於您正在處理的專案,這可能會經常改變。所有內容都需要為這一新約定進行更新。
大多數開發工具使用 go/build 包來查詢和載入 Go 原始碼。我們一直保持該包工作,但 API 沒有考慮到 modules,我們新增的用於避免 API 更改的變通方法比我們期望的要慢。我們釋出了一個替代品 golang.org/x/tools/go/packages。開發工具現在應該使用它。它同時支援 GOPATH 和 Go modules,並且速度更快,使用也更方便。在一兩個版本中,我們可能會將其移入標準庫,但目前 golang.org/x/tools/go/packages 是穩定且可用的。
Go Module 代理
modules 簡化 Go 開發的一種方式是將一組包的概念與它們儲存的底層原始碼儲存庫分離開來。
當我們與 Go 使用者談論依賴項時,幾乎所有在公司使用 Go 的人都詢問如何透過自己的伺服器路由 go get 包的獲取,以更好地控制可以使用哪些程式碼。即使是開源開發者也擔心依賴項消失或意外更改,導致他們的構建中斷。在 modules 之前,使用者嘗試了複雜的解決方案來解決這些問題,包括攔截 go 命令執行的版本控制命令。
Go modules 的設計使得引入一個模組代理的概念變得容易,該模組代理可以被請求特定的模組版本。
公司現在可以輕鬆執行自己的模組代理,其中包含關於允許內容和快取副本儲存位置的自定義規則。開源的 Athens 專案構建了一個這樣的代理, Aaron Schlesinger 在 2019 年的 Gophercon 上就此發表了演講。(一旦影片可用,我們會在此處新增連結。)
對於個人開發者和開源團隊,Google 的 Go 團隊 啟動了一個代理,作為所有開源 Go 包的公共映象,Go 1.13 在模組模式下將預設使用該代理。Katie Hockman 在 2019 年的 Gophercon 上就該系統發表了 演講。
Go Modules 狀態
Go 1.11 將 modules 作為實驗性的、可選的預覽引入。我們繼續進行實驗和簡化。Go 1.12 進行了改進,Go 1.13 將帶來更多改進。
modules 現在已經達到了我們認為它們將服務於大多數使用者的程度,但我們還沒有準備好關閉 GOPATH。我們將繼續進行實驗、簡化和修訂。
我們充分認識到,Go 使用者社群圍繞 GOPATH 積累了近十年的經驗、工具和工作流程,將所有這些轉換為 Go modules 需要一段時間。
但再次強調,我們認為 modules 現在對大多數使用者來說都會非常好,我鼓勵您在 Go 1.13 釋出時進行了解。
作為一個數據點,Kubernetes 專案有很多依賴項,他們已經遷移到使用 Go modules 來管理它們。您也可能可以。如果您不行,請透過 提交 bug 報告 告訴我們什麼對您不起作用或太複雜,我們將進行實驗和簡化。
工具
錯誤處理、泛型和依賴項管理至少還需要幾年時間,我們現在將專注於它們。錯誤處理已接近完成,modules 將是下一個,然後可能是泛型。
但如果我們展望未來幾年,當我們完成實驗、簡化和釋出了錯誤處理、modules 和泛型之後。然後呢?預測未來非常困難,但我認為一旦這三個都發布了,這可能標誌著一個主要變化的新平靜期的開始。屆時我們的重點可能會轉移到透過改進的工具來簡化 Go 開發。
一些工具工作已經開始,所以這篇文章最後將介紹這些。
雖然我們幫助更新了 Go 社群所有現有的工具來理解 Go modules,但我們注意到擁有大量執行一項小任務的開發輔助工具並沒有很好地服務於使用者。單個工具太難組合,呼叫起來太慢,而且太不統一,難以使用。
我們開始著手將最常用的開發助手統一到一個名為 gopls(發音為“go, please”)的工具中。Gopls 使用 語言伺服器協議 (LSP),並與任何支援 LSP 的整合開發環境或文字編輯器配合使用,目前幾乎所有編輯器都支援 LSP。
Gopls 標誌著 Go 專案關注點的擴充套件,從提供獨立的編譯器類命令列工具(如 go vet 或 gorename)擴充套件到提供完整的 IDE 服務。Rebecca Stambler 在 2019 年的 Gophercon 上就 gopls 和 IDE 進行了更詳細的演講。(一旦影片可用,我們會在此處新增連結。)
在 gopls 之後,我們還有想法可以以可擴充套件的方式復興 go fix,並使 go vet 更加有用。
結尾
這就是通往 Go 2 的道路。我們將實驗並簡化。然後實驗並簡化。然後釋出。然後實驗並簡化。然後重複這一切。它可能看起來甚至感覺像是在原地打轉。但每一次實驗和簡化,我們都會學到更多關於 Go 2 應該是什麼樣子,並朝著它邁出一步。即使是像 try、我們最初的四個泛型設計或 dep 這樣的被放棄的實驗也並非浪費時間。它們幫助我們瞭解在釋出之前需要簡化什麼,在某些情況下,它們幫助我們更好地理解了我們理所當然的一些東西。
總有一天,我們會意識到我們已經進行了足夠的實驗,進行了足夠的簡化,進行了足夠的釋出,然後我們就擁有了 Go 2。
感謝 Go 社群中的所有您幫助我們進行實驗、簡化、釋出,並在這條道路上找到方向。
下一篇文章: Contributors Summit 2019
上一篇文章: 為什麼需要泛型?
部落格索引